Dieser Unterschied ist jedoch nicht relevant, da Cassandra so arbeitet und da es sich um eine NoSQL-Datenbank handelt , ist es nicht erforderlich, diese Eigenschaften zu haben. Was wichtig ist und wir verwalten müssen, ist die Art und Weise, wie wir mit Cassandra über die Shell von CQL- Befehlen interagieren können.
CQL-Befehlskonsole
Im letzten Tutorial haben wir uns angesehen, wie die Cassandra- Struktur aufgebaut ist. Außerdem haben wir das OpsCenter gesehen , eine Weboberfläche, die uns hilft, verschiedene Aspekte unserer Datenbank zu visualisieren, aber die restlichen Funktionen fehlen, um richtig damit zu arbeiten.
Um mit der Datenbank arbeiten zu können, verwenden wir die CQL- Befehlskonsole, die in unserer Cassandra- Installation verfügbar ist und folgendermaßen ausgeführt werden sollte:
Jetzt können wir mit unserer aktiven und laufenden Kommandokonsole Anweisungen in Cassandra leeren. Bevor wir jedoch beginnen, Tabellen zu erstellen und mit ihnen zu arbeiten, müssen wir den Container für sie erstellen. Wenn wir uns an frühere Tutorials erinnern, wird dieser Container der Container genannt Schlüsselraum .
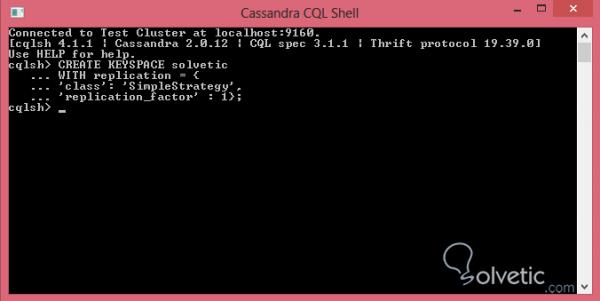
Der Schlüsselbereich hat nicht nur die Funktion, der Container der Tabellen zu sein, sondern ist auch für die Definition des Replikationsfaktors und der Strategie zuständig. Daher erstellen wir unseren ersten Schlüsselbereich über die Befehlskonsole und führen die folgenden Zeilen aus:
CREATE KEYSPACE solveticWITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
Zuerst erstellen wir unseren Schlüsselraum mit dem Namen solvetic und definieren mit WITH die Werte für die Replikation. In diesem Fall haben wir SimpleStrategy als Strategie ausgewählt, die für die Replikation der Informationen auf den nächsten verfügbaren Knoten verantwortlich ist. Darüber hinaus haben wir den Replikationsfaktor als 1 definiert, wodurch eine einzelne Kopie der Informationen erstellt wird. Wenn wir einen höheren Wert 3 angeben, können Leistungsprobleme auftreten, da wir nur einen Cluster und einen Knoten haben.
Um die CQL- Anweisung für die Erstellung des Schlüsselraums in unserer Befehlskonsole auszuführen, können wir Zeile für Zeile schreiben, um eine bessere Organisation unseres Satzes zu erreichen. Wir müssen nur wissen, dass es am Ende eines Satzes mit dem Semikolon da ist, wenn es wirksam wird:
Wenn wir die Werte unseres Schlüsselbereichs ändern möchten, können wir dies mit ALTER tun. Dies ist nützlich, wenn wir in eine Produktionsumgebung migrieren und den Replikationsfaktor ändern müssen. Sehen wir uns an, wie unsere CQL- Anweisung mit ALTER aussieht:
ALTER KEYSPACE solveticWITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 3};
Darüber hinaus können wir die Replikationsstrategie durch NetworkTopologyStrategy ändern, wodurch wir den Replikationsfaktor für verschiedene Rechenzentren definieren können. Siehe:
CREATE KEYSPACE solvetic WITH replication = {'class': 'NetworkTopologyStrategy', 'DC1': 1, 'DC2': 3};
Wie wir sehen, haben wir unsere Strategie geändert und für Rechenzentrum 1 oder DC1 den Replikationsfaktor 1 und für DC2 oder Rechenzentrum 2 den Faktor 3 definiert. Wenn wir einen Keyspace erstellen und ändern, können wir diesen eliminieren wir machen mit dem Wort DROP wie in der traditionellen SQL:
DROP KEYSPACE TechnoWikis;
Nachdem Sie die Grundlagen der Schlüsselbereiche in Cassandra kennengelernt haben , ist es an der Zeit, die Tabellen in unserem Schlüsselbereich zu erstellen.
Erstellung von Tabellen
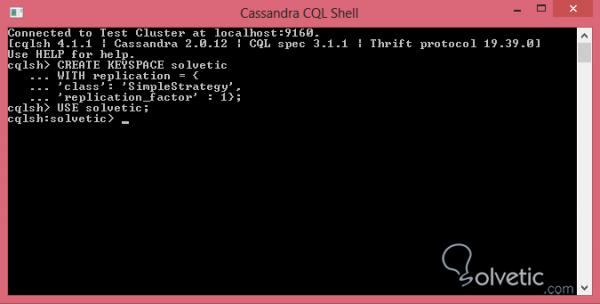
Die Erstellung von Tabellen in Cassandra ähnelt der Erstellung in relationalen Modellen, weist jedoch einige Unterschiede auf. Das erste, was wir tun müssen, um uns die Angabe des Schlüsselbereichs zu ersparen, ist die Verwendung. Dafür verwenden wir das reservierte Wort USE :
USE solvetic;
Wenn Sie USE verwenden, befindet sich alles, was wir von nun an tun, in diesem Schlüsselbereich . Wir sollten uns also keine Gedanken mehr machen, es anzuzeigen , und in der Befehlskonsole sollten wir den Schlüsselbereich angeben, in dem wir uns befinden:
Mit dieser letzten Überprüfung werden wir unsere erste Tabelle erstellen. Da die Syntax der von SQL sehr ähnlich ist, sehen wir uns an, wie unsere Benutzertabelle aussieht:
CREATE TABLE-Benutzer (Benutzertext, Kennworttext, Namenstext, Nachname-Text, Ländertext, PRIMARY KEY (Benutzer));
Wie wir sehen, ist es ganz einfach, viel mehr als herkömmliches SQL , wir definieren die Spalten und ihren Datentyp, schließlich definieren wir den Primärschlüssel und führen ihn aus. Die Befehlskonsole gibt nichts zurück, sondern gibt nur keinen Fehler aus. Wenn wir jedoch überprüfen möchten, ob unsere Tabelle erstellt wurde, können wir zwei Aktionen ausführen. wir können ein SELECT für unsere Tabelle ausführen, mal sehen:
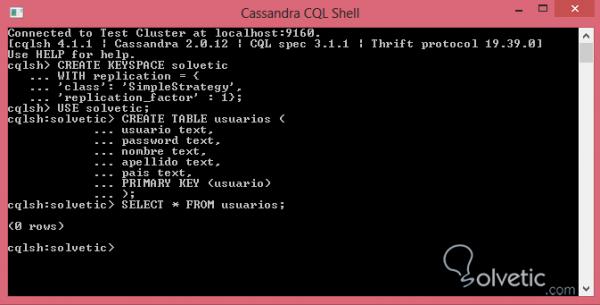
Wie wir sehen können, gibt es den Wert Null zurück, was in Ordnung ist, da wir keine Daten eingefügt haben. Die andere Möglichkeit, die wir haben und wenn wir visueller sind, besteht darin, die Tabelle im OpsCenter zu visualisieren. Dazu geben wir ein und gehen in den Datenbereich, wählen den Schlüsselbereich aus und dort lassen wir unsere Tabellen erstellen:
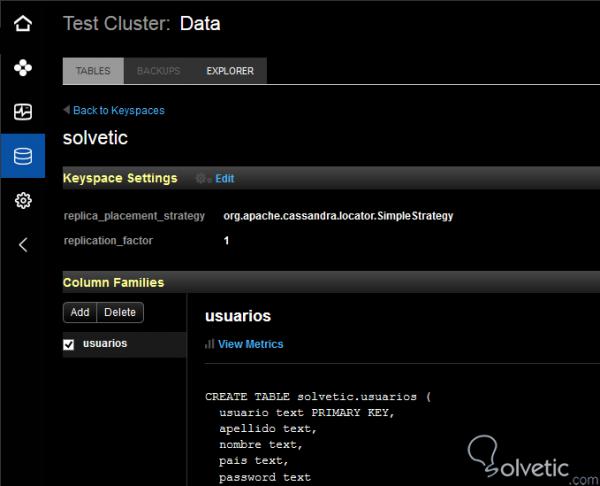
Der Primärschlüssel ist erforderlich, wenn wir die Tabelle erstellen. Im Gegensatz zum relationalen Modell können mehr als zwei Spalten vorhanden sein. Wenn wir einen einzelnen Primärschlüssel haben, können wir ihn nach dem Datentyp definieren:
CREATE TABLE-Benutzer (Benutzertext PRIMARY KEY, Kennworttext, Namenstext, Nachname-Text, Ländertext);
Der erste Primärschlüssel, der in Cassandra definiert ist, wird als Partitionsschlüssel oder Partitionsschlüssel bezeichnet und ist der Schlüssel, der jede Datenzeile identifiziert. Die folgenden Schlüssel, die wir angeben, sind die Clustering-Schlüssel und beeinflussen die Art und Weise, wie Cassandra die Informationen anordnet. Sehen wir uns nun an, wie wir das ausgedrückt haben, was in unserer CQL- Anweisung erklärt wurde:
Tutorial CREATE TABLE (Benutzertext, Zeitstempeldatum, Titeltext, Kategorietext, Inhaltstext, PRIMARY KEY (Benutzer, Datum));
Dies hat unsere Tutorial-Tabelle erstellt. Geben Sie mit unserem Partitionsschlüssel user und dem Clustering-Schlüsseldatum OpsCenter ein , um zu veranschaulichen , wie das Spaltendatum die Kriterien sind, nach denen Cassandra die Informationen sortiert:
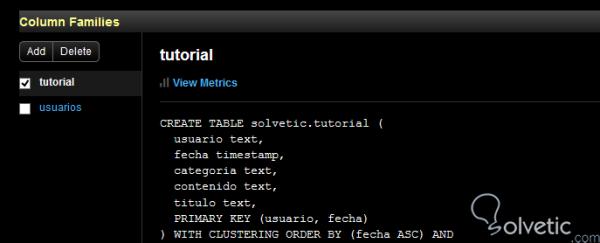
Wie wir dann sehen, wird das ***** durch Clustering über die Datumsspalte ASC erfolgen, und wie wir sehen konnten, war es recht einfach, diese Funktionalität in unserer Tabelle zu erstellen. Mit Cassandra können wir außerdem die ID einer Zeile mit Informationen aus einer anderen Spalte in viel kleineren Abschnitten kombinieren. Stellen Sie sich beispielsweise vor, dass jeder Benutzer mehr als 20 Tutorials hochlädt. Dann ist es am ratsamsten, diese Informationen durch Tutorials zu unterteilen. Sehen wir uns an, wie unsere neue Tabelle aussehen würde:
CREATE TABLE tutorial_por_usuarios (Benutzertext, Datum, Zeitstempel, Titeltext, Kategorietext, Inhaltstext, PRIMARY KEY ((Benutzer, Titel), Datum));
Was wir beim Erstellen dieses Tabellenstils beachten müssen, ist, dass wir nicht auf die Lernprogramme zugreifen können, sondern den Namen und den Titel des Benutzers angeben. Dies ist also etwas, das wir berücksichtigen müssen, wenn wir unser Modell für unsere Datenbank erstellen. wenn es das Optimalste für unseren Betrieb ist.
Zusätzliche Operationen
Neben der Erstellung unserer Tabelle und der Bereitstellung einiger nützlicher Funktionen für unser Datenmodell ist es wichtig, die anderen Operationen zu kennen, die wir in ihr ausführen können. Die erste ist die Änderung derselben, wir können den Datentyp der Spalten ändern (wann immer er gültig ist), Spalten hinzufügen oder löschen, die Informationen der Tabelle leeren und natürlich die Tabelle löschen.
Nehmen wir das Beispiel tutorial_panel, um den Rest der Operationen anzuwenden. Ändern wir zuerst den Datentyp der Textkategoriespalte nach Blobs . Sehen wir uns Folgendes an:
ALTER TABLE tutorial_by_users ALTER category TYPE blob;
Das Hinzufügen von Spalten ist ganz ähnlich wie bei SQL. Mit dem Wort ADD führen wir diese Operation aus, bei der wir eine Spalte mit dem Namen ruta_img hinzufügen :
ALTER TABLE tutorial_by_users ADD ruta_img text;
Wir haben unseren Satz in der Befehlskonsole ausgeführt und sind zu OpsCenter gegangen , um die Änderungen zu sehen, die auf unsere Tabelle angewendet wurden:
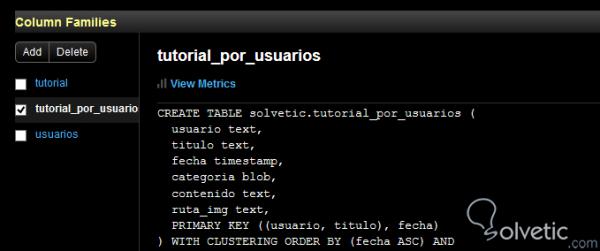
Wir sehen dann die vorgenommenen Änderungen, unsere Kategoriespalte mit einem neuen Datentyp und eine neue Spalte mit dem Namen route_img . Lassen Sie uns zum Abschluss des Lebenszyklus der Tabelle die verbleibenden destruktiven Operationen betrachten, bei denen wir mit TRUNCATE alle Informationen in unserer Tabelle leeren können:
TRUNCATE tutorial_by_users;
Schließlich beseitigen wir unsere Tabelle mit der bekannten DROP TABLE :
DROP TABLE tutorial_by_users;
Wie wir sehen, ist die Ähnlichkeit mit SQL genug, was das Hauptziel von Cassandra ist , dass Benutzer sich wohl fühlen, wenn sie damit arbeiten. Damit haben wir dieses Tutorial abgeschlossen, in dem wir feststellen konnten, dass es zwar theoretisch viel komplexer als die herkömmlichen relationalen Datenbanken ist, in der Praxis jedoch nicht nur leistungsstark und vielseitig ist, sondern auch extrem einfach zu handhaben und zu bearbeiten ist Erstellung unseres Datenmodells.