Jeden Tag werden in unserem Betriebssystem verschiedene Dateitypen heruntergeladen, erstellt und bearbeitet. In diesem speziellen Fall handelt es sich um Linux. Einer der häufigsten Fehler besteht darin, dass wir häufig mehrere doppelte Dateien haben , die nicht nur einen zusätzlichen Speicherplatz in der Datei belegen Festplatte, aber es kann zu Verwirrung beim Öffnen und Bearbeiten von Dateien führen.
In vielen Fällen haben wir auf unseren Desktops oder Servern verschiedene Dateien, unabhängig vom Format, dupliziert und wir wissen es nicht. Dadurch wird unnötig Speicherplatz belegt und es kann mit einer falschen Datei gearbeitet werden, da wir die eine bearbeiten und die andere öffnen können usw. Ein praktischer Weg, um unsere Arbeitsumgebung besser zu organisieren, besteht darin, diese doppelten Dateien zu erkennen und zu entfernen , sodass auf diese Weise nur eine einzige Datei verwendet werden kann.
Es lohnt sich, diese Aufgabe nicht nur zu erledigen, um Duplikate löschen zu können, sondern auch, um Suchen durchzuführen, bei denen wir Dateien löschen und löschen können, die wir nicht mehr wollen, die wir aber von verschiedenen Teilen des Linux-Betriebssystems wiederholt haben. Es spielt keine Rolle, wie es unter anderem in Fedora, Ubuntu, Debian und CentOS sein kann.
Wir haben zu seiner Zeit gesehen, wie man doppelte Dateien in Windows findet. Hier konzentrieren wir uns auf Linux-Umgebungen, in denen wir sowohl grafische als auch Befehlszeilen-Tools haben, die uns helfen, diese Dateien zu finden und diejenigen zu entfernen, die wir für nicht nützlich halten.
TechnoWikis erklärt, wie doppelte Dateien in Linux auf einfache, aber funktionale Weise erkannt und beseitigt werden können.
- Wenn A beim Scannen eines Eingabearguments vor B gefunden wurde, hat A eine höhere Bewertung.
- Wenn A in einer Tiefe von weniger als B gefunden wurde, hat A eine höhere Bewertung.
- Wenn A vor B gefunden wurde, hat A eine höhere Bewertung.
- Für jedes Argument in der Befehlszeile wird eine Schleife erstellt, und jedem Argument wird in aufsteigender Reihenfolge eine Prioritätsnummer zugewiesen.
- Für jedes Argument wird der Inhalt des Verzeichnisses rekursiv aufgelistet und der Dateiliste zugewiesen.
- Rdfind weist jedem Argument eine Verzeichnistiefen-Nummer zu, die bei 0 beginnt.
- Wenn das Eingabeargument eine Datei ist, wird es der Dateiliste hinzugefügt.
- Anschließend wird die Liste gescannt und die Größe aller Dateien ermittelt.
- Wenn das Flag “-removeidentinode” wahr ist, werden die bereits hinzugefügten Elemente der Liste entsprechend der Kombination aus Gerätenummer und Inode entfernt.
- Die Dateien werden nach Größe sortiert. Anschließend werden die Dateien in der Liste gelöscht, die eindeutige Größen haben.
- Es ist nach Gerät und Inode geordnet (beschleunigt das Lesen von Dateien).
- Die Dateien in der Liste, die dieselbe Größe, aber unterschiedliche erste Bytes haben, werden gelöscht.
- Die Prüfsumme wird für jede Datei ausgeführt.
- Es werden nur Dateien in der Liste mit derselben Größe und Prüfsumme beibehalten. Dies sind die Duplikate.
- Sortieren Sie die Liste nach Größe, Prioritätsnummer und Tiefe. Die erste Datei jedes Satzes von Duplikaten wird standardmäßig als Original betrachtet.
- Wenn Sie “-makeresultsfile true” aktivieren, wird die Ergebnisdatei gedruckt (Standardeinstellung).
- Wenn das Flag “-deleteduplicates true” ist, werden doppelte Dateien gelöscht.
- Wenn der Indikator “-makesymlinks true” ist, werden die Duplikate durch einen symbolischen Link zum Original ersetzt.
- Wenn das Ergebnis “-makehardlinks true” ist, werden Duplikate mit Link zum Original ersetzt.
1. Suchen Sie doppelte Dateien mit dem Dienstprogramm Rdfind unter Linux
Um Rdfind unter Linux zu installieren, können wir einen der folgenden Befehle ausführen:
sudo apt install rdfind (Debian / Ubuntu / Mint) sudo yum installiere epel-release && $ sudo yum installiere rdfind (CentOS / RHEL) sudo dnf installiere rdfind (Fedora)
Sobald Rdfind heruntergeladen und installiert ist, führen wir es in einem einfachen Verzeichnis wie folgt aus:
rdfind / home / TechnoWikis
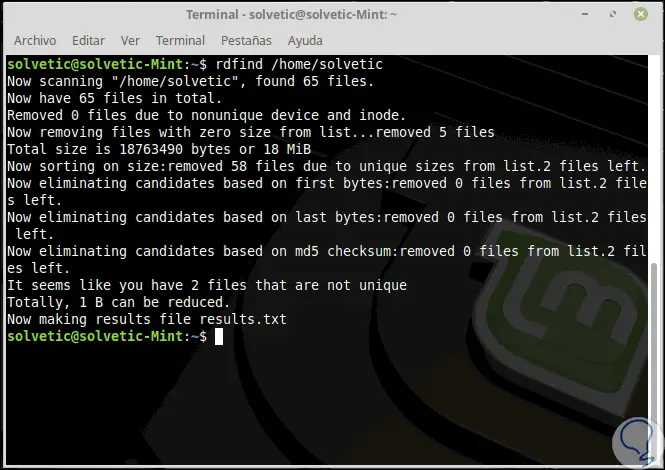
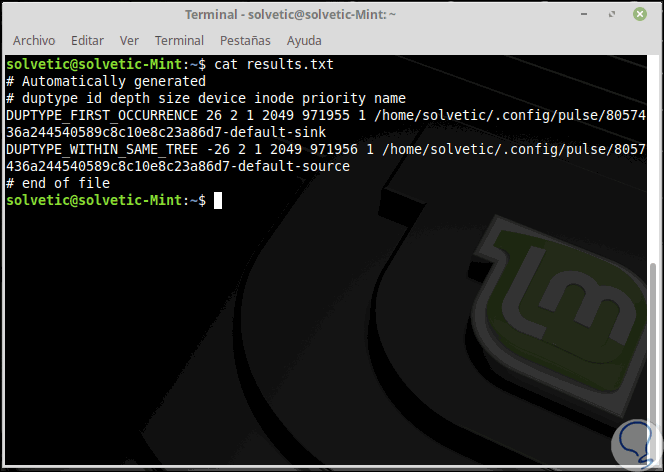
Dort können wir sehen, dass die Anzahl der Dateien in diesem Verzeichnis erkannt wird und angezeigt wird, ob sie gelöscht wurden oder keine doppelten Dateien vorhanden sind. Das Dienstprogramm Rdfind speichert die Ergebnisse in einer Datei results.txt, die sich in demselben Verzeichnis befindet, in dem Sie das Programm ausgeführt haben. Der Inhalt wird mit cat angezeigt:
cat results.txt
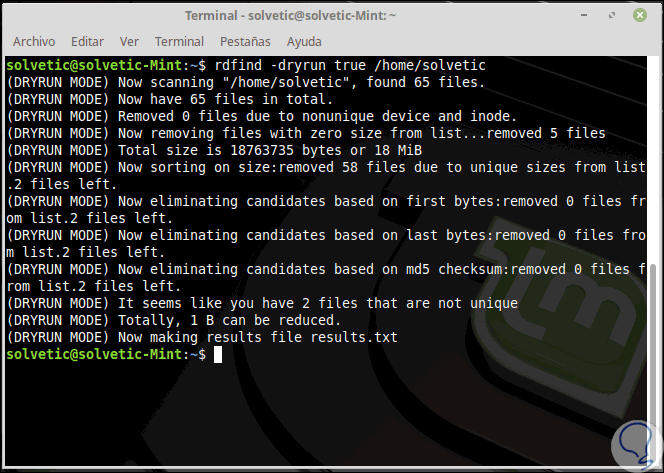
Eine zusätzliche Aufgabe für rdfind ist die Verwendung des Parameters “-dryrun”, mit dem eine Liste der Duplikate angezeigt wird, ohne dass eine Aktion ausgeführt werden muss:
rdfind -dryrun true / home / TechnoWikis
Falls Duplikate erkannt werden, können diese auch durch Hardlinks ersetzt werden.
rdfind -makehardlinks true / home / user
Um die Duplikate zu beseitigen, müssen wir Folgendes ausführen:
rdfind -deleted dupliziert true / home / user
Um auf die Hilfe von Rdfind zuzugreifen, verwenden wir den folgenden Befehl:
Mann rdfind
2. Suchen Sie mit dem Dienstprogramm Fdupes unter Linux nach doppelten Dateien
Eine andere Option, die wir in Linux haben, um diese doppelten Dateien zu validieren, ist Fdupes. Es ist ein Befehlszeilen-Tool, mit dem wir genau beobachten können, welche Dateien Duplikate im System haben. Fdupes ist ein Programm, das entwickelt wurde, um doppelte Dateien in bestimmten Verzeichnissen unter Linux zu identifizieren oder zu entfernen. Es ist Open Source, kostenlos und in C geschrieben.
- Vergleich partieller md5sum-Signaturen.
- Vergleich aller md5sum-Signaturen.
- Überprüfung des Vergleichs byteweise.
Bei der Verwendung von Fdupes haben wir Verwendungsoptionen wie:
- Rekursive Suche
- Leere Dateien ausschließen.
- Stellen Sie die Größe doppelter Dateien bereit.
- Duplikate sofort entfernen.
- Schließen Sie Dateien mit unterschiedlichen Eigentümern aus.
Standardmäßig ist dieses Tool nicht installiert, daher müssen wir den folgenden Befehl für die Installation eingeben. Um Fdupes zu installieren, führen wir den folgenden Befehl aus:
sudo apt install fdupes
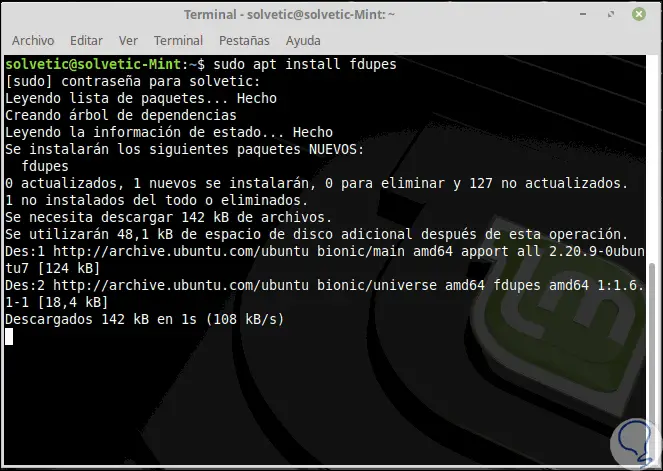
Einmal heruntergeladen, können wir die folgende Zeile für eine einfache Suche ausführen. Dort werden die doppelten Dateien angezeigt.
fdupes / route zu suchen
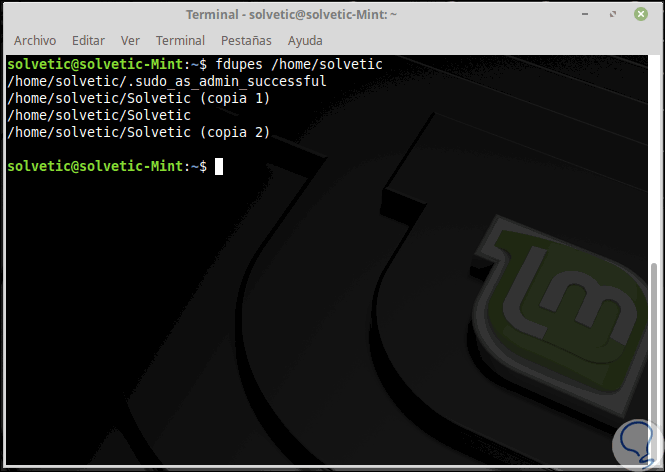
Um eine rekursive Suche auszuführen, verwenden wir die folgende Zeile:
fdupes -r / Route zu suchen
Es ist auf folgende Weise möglich, mehrere Verzeichnisse und ein Verzeichnis für die rekursive Suche anzugeben:
fdupes <dir1> -r <dir2>
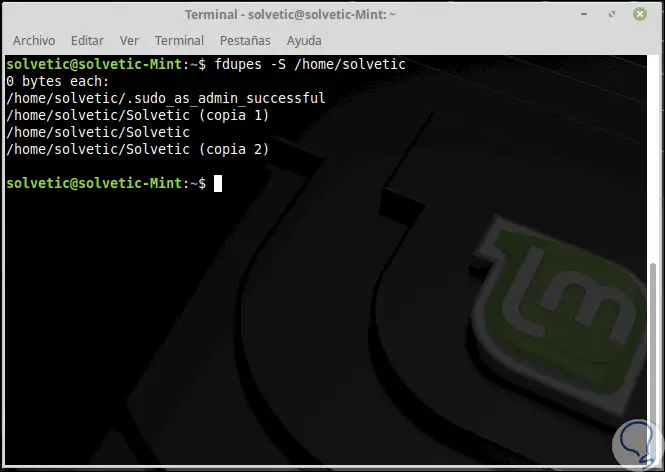
Wenn Fdupes die Größe der doppelten Dateien berechnen soll, verwenden wir die Option -S:
fdupes -S <dir>
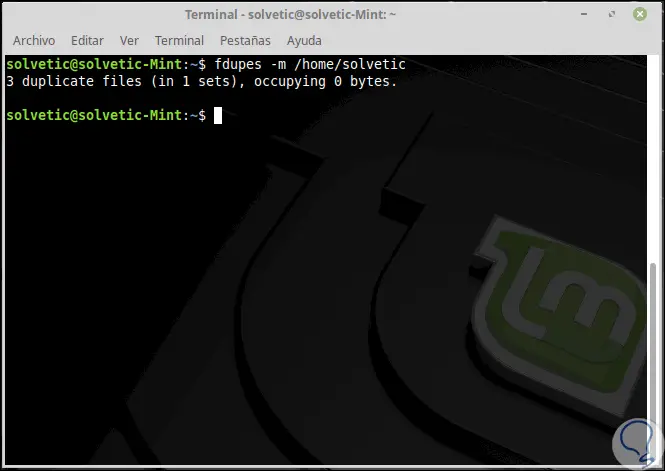
Um zusammenfassende Informationen zu den gefundenen Dateien zu sammeln, verwenden wir die Option -m:
fdupes -m <dir>
Wenn Sie alle Duplikate löschen möchten, führen wir Folgendes aus:
fdupes -d <dir>
Wenn wir auf die Hilfe des Dienstprogramms zugreifen möchten, führen wir Folgendes aus:
fdupes -help
Einige der allgemeinen Verwendungsmöglichkeiten sind:
-r -recurse
-R --recurse
-s -symlinks
-H-Hardlinks
-n -noempty
-A -nicht versteckt
-S-Größe
-d -delete
-q-leise
-o - ***** = BY
-l --log = LOGFILE
-v -version
-h - hilfe
3. Suchen Sie unter Linux mit dem Dienstprogramm FSlint nach doppelten Dateien
Ein weiteres, das wir verwenden werden, ist FSlint, das standardmäßig in den verschiedenen Linux-Ditros wie Ubuntu, Debian, Fedora usw. enthalten ist. Um mehr über FSlint zu erfahren, können wir den folgenden Link besuchen:
Wir können FSlint im Menü “Aktivitäten” nach seiner Verwendung durchsuchen. 
Nach dem Öffnen muss die Anwendung installiert werden. Dazu genügt es, auf die Schaltfläche Installieren zu klicken, und der Installationsvorgang des Dienstprogramms beginnt. 
Sobald das Tool installiert wurde, fahren wir mit seiner Ausführung fort und sehen die folgende Umgebung:
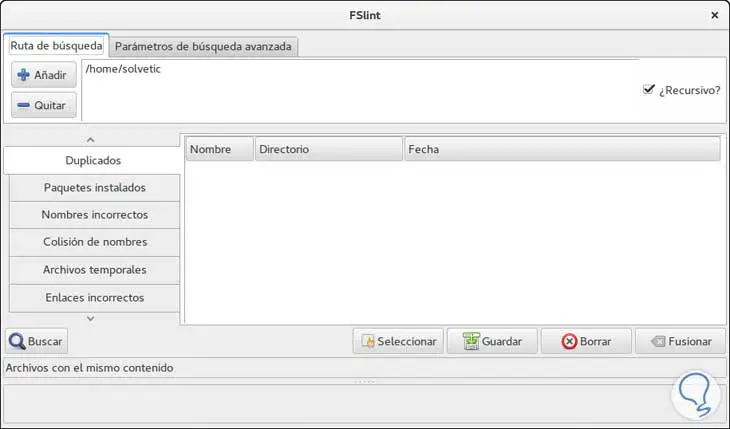
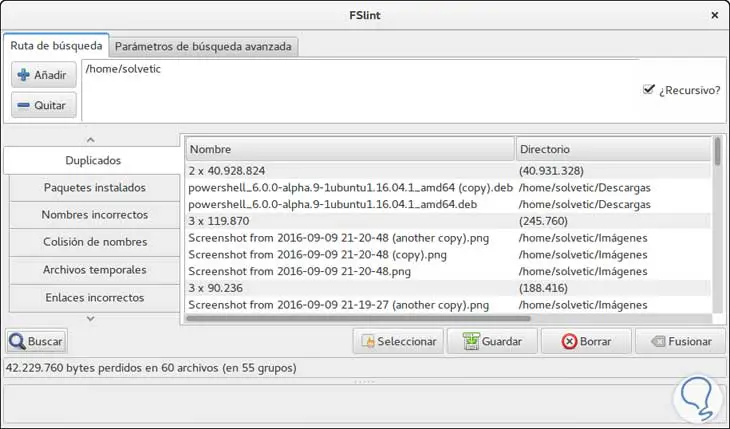
Um den Suchvorgang für alle doppelten Dateien zu starten, klicken Sie auf die Schaltfläche “Suchen” am unteren Rand. Das Ergebnis ähnelt diesem. Dort können wir die nicht benötigten Dateien auswählen und über die Schaltfläche Löschen löschen. Das FSlint-Tool kann auch vom Terminal in Ubuntu 16 aus verwendet werden.
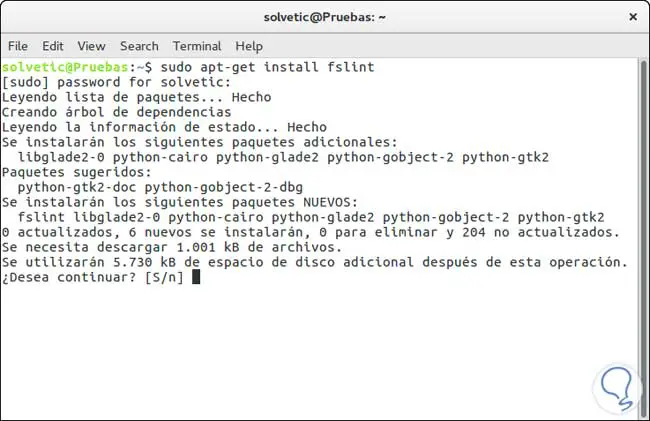
Wenn wir das Tool vom Terminal aus installieren möchten, geben wir den folgenden Befehl ein:
sudo apt-get installiere fslint
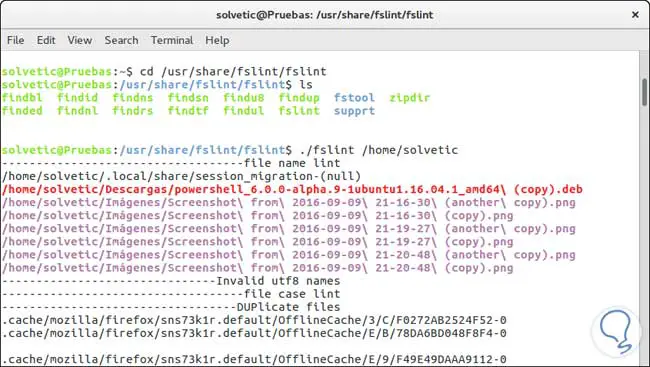
Sobald FSlint installiert ist, geben wir die folgenden Befehle ein, um FSlint zu verwenden. Wir können sehen, dass alle Dateien, die wir im System dupliziert haben, angezeigt werden.
cd / usr / share / fslint / fslint (Dies ist der Standardpfad in Ubuntu) ./fslint / Pfad zum Suchen von Dateien
Wir können sehen, dass wir zwei praktische Optionen haben, um doppelte Dateien in Linux-Umgebungen zu erkennen und zu beseitigen und so den Speicherplatz und die zu verwendenden Dateien besser zu verwalten.
