In früheren Tutorials haben wir uns auf die Struktur und damit die Erstellung der Tabellen in Cassandra konzentriert . Wir haben ausführlich gelernt, wie man mit den Datentypen arbeitet, die Eigenschaften der Tabellen definiert und sogar der Engine mitteilt, wie die Organisation unserer Informationen sein soll .
Mit diesem Wissen können wir zu komplexeren Aspekten übergehen, die in der Welt der Datenbanken eine Einheit bilden. Dies ist die Manipulation von Informationen in unserer Umgebung. Lassen Sie uns sehen, was wir mit Cassandra erreichen können.
Das Einfügen von Informationen in eine Datenbank ist eine der Hauptoperationen, von denen die anderen abgeleitet werden. In Cassandra ist es recht einfach und hat eine gewisse Ähnlichkeit mit der herkömmlichen SQL-Syntax. Es wird das Wort INSERT INTO gefolgt vom Namen der Tabelle gefolgt von den Spalten verwendet und mit VALUES werden die einzufügenden Informationen angegeben.
Wir werden die Tabellen verwenden, die in früheren Tutorials verwendet wurden. Die CQL- Tabelle wird jedoch unten für einige dieser Tabellen für Benutzer angezeigt, die sie nicht in ihrer Umgebung haben:
CREATE TABLE Benutzer ( Benutzertext, Passworttext, Name Text, Nachname Text ländertext, PRIMARY KEY (Benutzer) ); Tutorial TABELLE ERSTELLEN ( Benutzertext, Datum Zeitstempel, Titeltext, Textkategorie, Textinhalt, PRIMARY KEY (Benutzer, Datum) );
Mit den erstellten Tabellen werden wir nun die erste Einfügung in die Benutzertabelle vornehmen. Dies ist recht einfach, da alle Spalten vom Typ Text sind. Schauen wir uns nun an, wie unsere CQL- Anweisung lautet:
INSERT IN Benutzer (Benutzer, Passwort, Vorname, Nachname, Land) WERTE ("jacosta", "123456", "Jon", "Acosta", "Spanien");
Da alle Werte für den Texttyp nur in einfachen Anführungszeichen angegeben werden mussten, überprüfen wir, ob die Einfügung erfolgreich war, indem Sie ein SELECT für unsere Tabelle ausführen:
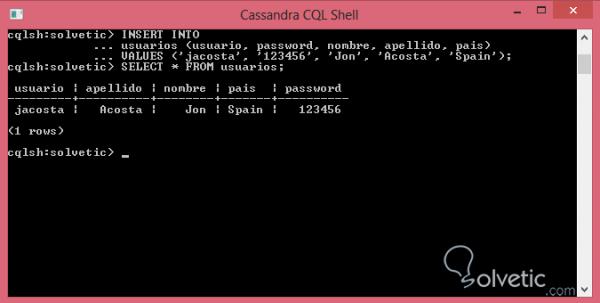
Wie wir sehen konnten, war das Einfügen erfolgreich und wenn wir die Operation mit ihrem Paar in SQL vergleichen, war es viel einfacher auszuführen, wir werden ein weiteres Einfügen von Daten durchführen, aber diesmal in unserer Tutorial-Tabelle, wo wir ein Feld vom Typ Zeitstempel haben :
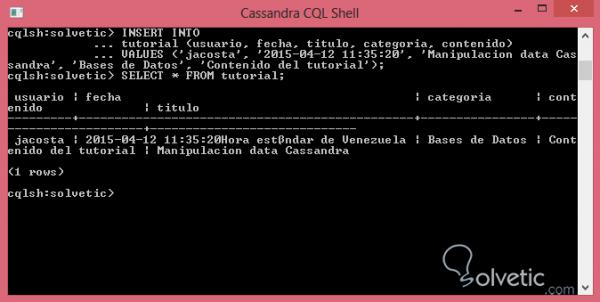
INSERT IN Tutorial (Benutzer, Datum, Titel, Kategorie, Inhalt) WERTE ('jacosta', '2015-04-12 11:35:20', 'Manipulationstermine Cassandra', 'Datenbanken', 'Inhalt des Tutorials');
Da wir es für das Einfügen von Zeitstempeldaten zu schätzen wissen, wenn wir einfach der entsprechenden Struktur folgen, können wir dies problemlos tun. Wir haben eine Abfrage in unserer Tabelle durchgeführt, die so aussehen sollte:
Manchmal können die Informationen in unserer Datenbank, wie bei jeder Entwicklung zu erwarten, geändert werden. Dazu müssen wir die Datensätze mit UPDATE aktualisieren, aber Cassandra funktioniert anders als im relationalen Modell Die Syntax zuerst:
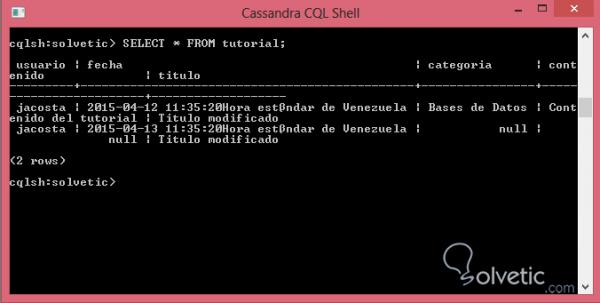
UPDATE Tutorial SET title = 'Geänderter Titel' WHERE user = 'jacosta' AND date = '2015-04-13 11:35:20';
Wir konnten das Update problemlos durchführen, allerdings wird bei der Aktualisierung in Cassandra eine neue Spalte innerhalb der Zeile mit dem neuesten Zeitstempel hinzugefügt und die alten Spalten mit einer Art von Markern markiert. Diese Markierungen sind in keiner Weise wirksam Sofort, aber wenn Cassandra eine Frage stellt, überprüft sie die beiden Spalten und wer den letzten Zeitstempel hat, gewinnt.
Cassandra unterscheidet sich auch in Bezug auf das Einfügen von Daten in Bezug auf traditionelle SQL-Datenbanken. Wenn wir beispielsweise versuchen, dieselben Werte mit dem Benutzer jacosta einzufügen, der der Primärschlüssel ist, erhalten wir eine Fehlermeldung, aber Cassandra ist anders und ihre Mission ist es Spalten einfügen. Die Besonderheit dabei ist, dass Cassandra , wie in der Aktualisierung der Informationen erwähnt, die neuere Zeile zurückgibt. Wir fügen Daten mit demselben Benutzer ein und variieren den Rest der Informationen:
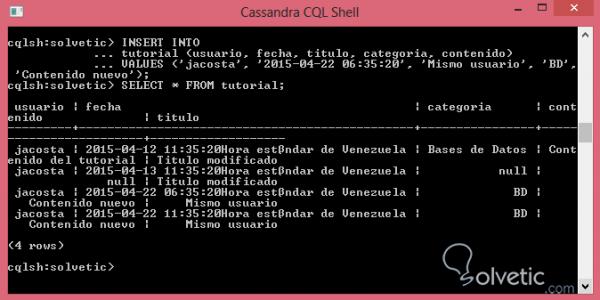
INSERT IN Tutorial (Benutzer, Datum, Titel, Kategorie, Inhalt) WERTE ('jacosta', '2015-04-22 06:35:20', 'Gleicher Benutzer', 'BD', 'Neuer Inhalt');
Wenn wir unsere Tabelle konsultieren, sehen wir, dass sich alle Datensätze in ihr befinden, unabhängig davon, ob sie denselben Primärschlüssel wie im folgenden Bild wiederholen, in dem wir auch überprüfen können, ob beim Ausführen von INSERT kein Fehler generiert wurde:
Um die Informationen zu entfernen, arbeitet Cassandra anders als in der gewöhnlichen SQL-Syntax, in der die WHERE-Klausel nicht verwendet werden muss, um die Informationen zu entfernen. Wenn sie ausgeführt werden, werden alle Datensätze in der Tabelle entfernt, was sehr gefährlich ist, da wir verlieren können unsere Informationen aufgrund des Missbrauchs des Satzes.
Cassandra macht die Verwendung der WHERE- Klausel obligatorisch, um unsere Informationen zu schützen. Wir werden die Aufzeichnungen entfernen , die den Benutzer jacosta treffen:
AUS Tutorial LÖSCHEN WHERE user = 'jacosta';
Dadurch werden alle Tutorials entfernt, die vom angegebenen Benutzer hochgeladen wurden. Dies ist nicht schlecht, aber bei weitem nicht optimal. Wir verwenden den Rest der angegebenen Schlüssel, in diesem Fall das Clustering-Schlüsseldatum . Lassen Sie uns sehen, wie unser CQL-Satz ist :
AUS Tutorial LÖSCHEN WO user = 'jacosta' UND date = '2015-04-22 06:35:20';
Sehen wir uns dann im folgenden Bild an, wie wir zwei Datensätze mit demselben Benutzer oder Primärschlüssel zur Verfügung haben, und mit unserem spezifischeren DELETE konnten wir die gewünschte Registrierung eliminieren:
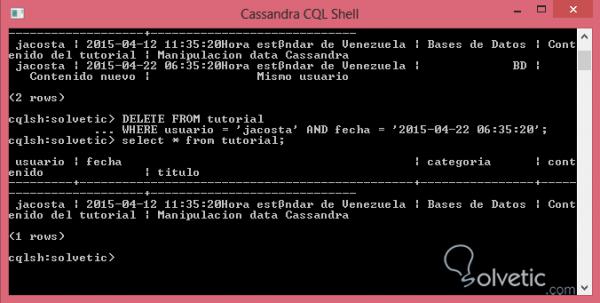
Bisher konnten wir verschiedene Arten der Informationsmanipulation beobachten, aber all diese sind recht einfach zu implementieren und wir haben SELECT verwendet , um die durch diese Operationen vorgenommenen Änderungen zu konsultieren. Diese Klausel enthält jedoch viel mehr als nur das, was in Sicht ist. Dabei ähnelt die Syntax zwar der von SQL, das Verhalten kann jedoch variieren.
Eine dieser Variationen oder Unterschiede, die SELECT der CQL- Sprache in Bezug auf SQL aufweist, sind die folgenden:
Die Erstellung der Abfragen war bisher recht einfach, da wir den Namen der Schlüsselbereiche, Tabellen und Spalten kannten. Was passiert jedoch, wenn wir die Namen für unsere Abfragen nicht kennen? In diesen Fällen haben wir den Befehl DESCRIBE , den wir zuerst ausführen, um die Schlüsselbereiche zu identifizieren:
Beschreibe die Keyspaces;
Mal sehen, wie die Ausführung des Befehls aussieht:
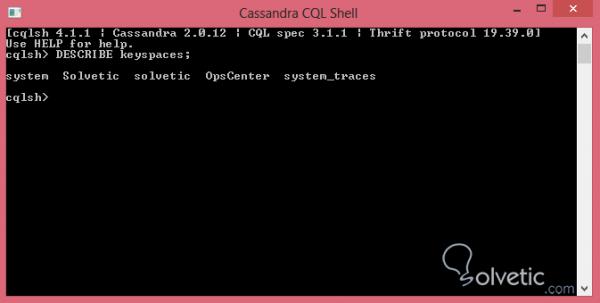
Wie wir sehen können, ist es sehr nützlich und ermöglicht es uns, alle in unserem Cluster vorhandenen Schlüsselbereiche abzurufen . Zusätzlich können wir DESCRIBE verwenden , um die in den Schlüsselbereichen verfügbaren Tabellen anzuzeigen. Sehen wir uns an, wie dies aussieht:
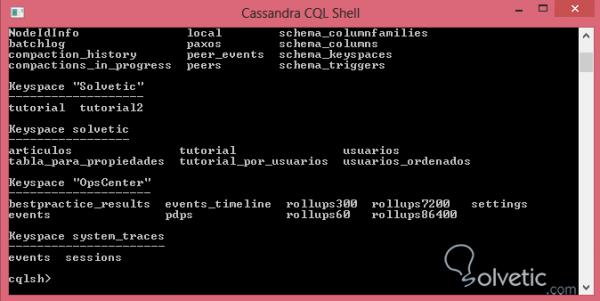
Wie wir sehen können, gibt Cassandra uns eine Liste der Schlüsselbereiche und der darin enthaltenen Tabellen, jedoch geht der Befehl DESCRIBE noch einen Schritt weiter und wir können in der Struktur noch eine Ebene tiefer gehen, da uns die am meisten interessieren In den Spalten einer bestimmten Tabelle sehen wir uns das Ergebnis an, das von der Befehlskonsole ausgegeben wird:
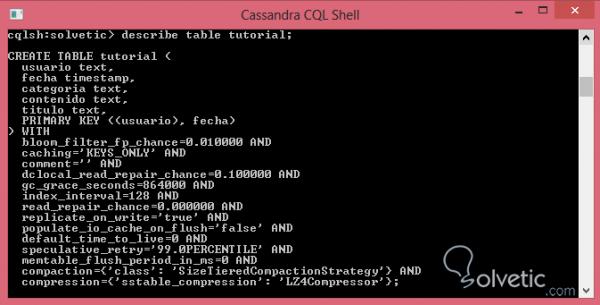
Wie wir sehen konnten, ist der DESCRIBE- Befehl ziemlich mächtig, da er nicht nur den Namen der Spalten unserer Tabelle zurückgibt, sondern auch den Datentyp für jede der Spalten und sogar die Eigenschaften wie Kommentare, Komprimierung und Komprimierung durch erwähne einige.
Da wir bereits wissen, dass Sie unsere Tabelle haben, können wir unseren SELECT- Befehl effektiv anwenden, wobei wir nur die Spalten auswählen können, die wir benötigen:
SELECT Benutzer, Datum, Titel FROM Tutorial;
Oder filtern Sie einfach nach einem bestimmten Benutzer:
SELECT Benutzer, Datum, Titel FROM Tutorial WHERE Benutzer = 'jacosta';
Wir können sogar nach mehreren Benutzern filtern, wenn wir aus der SQL- Welt kommen, können wir den OR- Operator anwenden, der jedoch in Cassandra nicht vorhanden ist. Dazu müssen wir IN verwenden.
SELECT Benutzer, Datum, Titel FROM Tutorial WHERE Benutzer IN ('jacosta', 'cperez');
Schließlich können wir unsere Informationen nach Bereichen filtern. In diesem Fall können wir einen Filter nach Datumsbereich anwenden. Wenden Sie dazu einfach die Operatoren größer als und kleiner als an, zusammen mit UND können wir es erreichen. Mal sehen, wie wir aussehen würden:
SELECT Benutzer, Datum, Titel FROM Tutorial WHERE Benutzer = 'jacosta' AND Datum> '2015-04-12' AND Datum <'2015-04-26';
Mit diesem letzten haben wir dieses Tutorial beendet, in dem wir sehen konnten, wie Cassandra nicht nur mächtig, sondern auch sehr einfach zu verwalten ist. Sie gibt uns eine Syntax, wie wir sie gewohnt sind, wenn wir aus der SQL- Welt kommen, um die notwendigen Operationen für die Manipulation von Informationen in unseren Tabellen auszuführen.