Wie oft mussten wir unsere Dienste bereithalten, oder vielmehr, um unsere Dienste immer verfügbar zu halten, und wie oft ist die Festplatte unseres Servers beschädigt, und wir haben kein Backup. Nun, angesichts dieser Umstände habe ich beschlossen, dieses Lernprogramm zu erstellen um sicherzustellen, dass unsere Server oder besser gesagt unsere Dienste immer online sind .
In Anbetracht dessen, dass das Tutorial für fortgeschrittene Linux-Benutzer gedacht ist, werde ich Themen wie die Installation des Basissystems nicht ansprechen, da ich dieses Mal CentOS 6 64-Bit in seinem neuesten Update verwenden werde. Ebenso werde ich nur erwähnen, was für den Betrieb des Clusters unbedingt erforderlich ist (Hochverfügbarkeitsserver).
Ich möchte auch darauf hinweisen, dass dieser Leitfaden darauf abzielt, den Webdienst immer aktiv zu halten, obwohl ich ihn mit anderen Diensten erfolgreich verwendet habe. Ich denke, als Einstieg oder besser als Einstieg ist es am einfachsten, einen Server zu erstellen Web-Cluster.
Kommen wir ohne weiteres zum Guten.
2. Festplatte 80 GB
3. Celeron-Prozessor
4. Partitionierung der Daten für den Cluster (die Größe, die Sie erstellen möchten)
5. Betriebssystem CentOS 6 (in seinem neuesten Update)
Wenn Sie die Anforderungen erfüllen, starten Sie die Installation des Linux-Clusters .
Im Folgenden wird der DRBD für die Synchronisation der Partitionen auf beiden Servern installiert. Hierzu müssen die folgenden Anweisungen in Shell ausgeführt werden :
[root @ node1 ~] rpm -ivh http://elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm
[root @ node1 ~] yum install -y kmod-drbd83 drbd83-utils
(Persönlich benutze ich die 8.3, da die 8.4 mir Probleme mit einigen Distributionen gab)
[root @ node1 ~] modprobe drbd
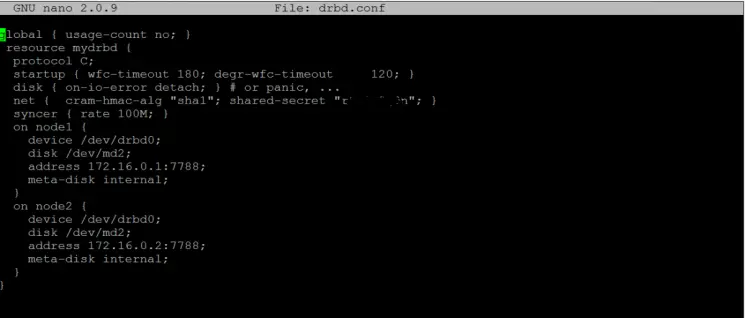
resource mydrbd { #dies ist der Name der Ressource Protokoll C; Start {WFC-Timeout 180; degr-wfc-timeout 120;} # 180 Sekunden warten auf das Slave-Gerät, 120 Sekunden, wenn es nicht antwortet, verschlechtert es sich und bleibt sekundär disk {on-io-error detach; } net {cram-hmac-alg "sha1"; shared-secret "geheimer Schlüssel";} #In diesem Teil geben Sie einen Schlüssel mit der sha1-Verschlüsselung an, dieser Schlüssel dient zur Kommunikation zwischen den beiden Knoten. Syncer {Rate 100M;} # Synchronisationsgeschwindigkeit, es ist egal, ob wir eine Gigabit-Netzwerkkarte haben, es funktioniert nicht bei 1000M, die empfohlene maximale Geschwindigkeit ist 100M (ich habe es mit 10M installiert und es funktioniert super, ein bisschen langsam die erste Synchronisation, aber dann kann man den Unterschied nicht sehen ) auf node1 { device / dev / drbd0; # hier geben wir an, welches gerät für das drbd reserviert ist, wir können mehrere geräte für verschiedene daten oder verschiedene dienste haben, unter anderem SAMBA, MySQL disk / dev / md2; # Die Partition, die für DRBD verwendet wird, ist angegeben Adresse 172.16.0.1:7788; # Wir geben eine IP außerhalb des Bereichs unseres Netzwerks an. Erwähnenswert ist, dass das Netzwerkkabel direkt zwischen Servern angeschlossen werden muss, ohne über einen Switch oder Hub zu gehen. Wenn es sich um neuere Netzwerkkartenmodelle handelt, ist kein Crossover-Kabel erforderlich. Meta-Disk intern; } auf node2 { # Die Spezifikationen des zweiten müssen mit denen des ersten identisch sein. Ändern Sie nur die IP-Adresse. Es muss sich um denselben Port handeln. Dies liegt daran, dass wenn wir zwei Cluster zusammen haben, diese in Konflikt geraten und nicht ordnungsgemäß funktionieren. Wenn wir mehrere Cluster haben möchten, wird empfohlen, verschiedene Ports zu verwenden. Erwähnenswert ist, dass diese Ports auf beiden Knoten gleich sein müssen. device / dev / drbd0; disk / dev / md2; Adresse 172.16.0.2:7788; Meta-Disk intern; } }
/ etc / hosts 192.168.1.1 node1 #name von node1 im lokalen Netzwerksegment 192.168.1.2 node2 #name von node2 im lokalen Netzwerksegment 172.16.0.1 knoten1 #name von knoten1 im synchronisationsnetzwerksegment 172.16.0.2 knoten2 # knoten2 name im synchronisationsnetzwerk segment
[root @ node1 ~] drbdadm create-md disk1
/etc/init.d/drbd start
drbdadm - Überschreibe Daten von Peer-Primärdatenträger1
cat / proc / drbd
Die Antwort des vorherigen Befehls sieht ungefähr so aus:
version: 8.3.15 (api: 88 / proto: 86-97) GIT-Hash: 0ce4d235fc02b5c53c1c52c53433d11a694eab8c Erstellt von phil @ Build32R6, 20.12.2012 20:23:49 1: cs: SyncSource ro: Primär / Sekundär ds: UpToDate / Inkonsistent Cr-n- ns: 1060156 nr: 0 dw: 33260 dr: 1034352 at: 14 bm: 62 lo: 9 pe: 78 ua: 64 ap: 0 ep: 1 wo: f oos: 31424 [=================>.] synchronisiert: 97,3% (31424/1048508) K Ziel: 0:00:01 Geschwindigkeit: 21.240 (15.644) K / Sek # Hier können wir sehen, dass die Synchronisation auf 97,3% geht und angibt, dass dies der primäre Knoten ist und der sekundäre als inkonsistent erscheint, da die Synchronisation noch nicht abgeschlossen ist. # Wenn wir fertig sind, führen wir cat / proc / drbd erneut aus und haben Folgendes: version: 8.3.15 (api: 88 / proto: 86-97) GIT-Hash: 0ce4d235fc02b5c53c1c52c53433d11a694eab8c Erstellt von phil @ Build32R6, 20.12.2012 20:23:49 1: cs: Connected ro: Primär / Sekundär ds: UpToDate / UpToDate Cr-- ns: 1081628 nr: 0 dw: 33260 dr: 1048752 al: 14 bm: 64 lo: 0 pe: 0 ua: 0 ap: 0 ep: 1 wo: f oos: 0 # Wenn wir die UpToDate-Nachricht zurückgeben, wissen wir, dass die Synchronisation abgeschlossen ist und die drbd-Partitionen genau gleich sind.
mkfs.ext3 / dev / drbd1
Ich verwende ext3, weil es mir gute Stabilität gegeben hat, aber wir könnten auch ext4 verwenden. Ich empfehle nicht, eine Partition unterhalb von ext3 zu verwenden.
Bisher können wir die Partition / dev / drbd1 an jedem Punkt der Systemassembly manuell bereitstellen. In meinem Fall verwende ich / home für die Assembly, da jeder der registrierten Benutzer auf beiden Knoten ein eigenes Verzeichnis für Webseiten hat Deshalb führe ich aus:
mounten Sie -t ext3 / dev / drbd1 / home
Und ich beginne, Benutzer für die Datenreplikation auf beiden Servern zu erstellen. Das Folgende ist die Installation von Heartbeat , einer Anwendung, mit der sich die Server gegenseitig überwachen, und die dafür verantwortlich ist, die relevanten Änderungen vorzunehmen, wenn die primäre aus irgendeinem Grund ausfällt und die Anwendung konvertiert sekundär in primär, um die Funktionalität des Systems sicherzustellen.
Für die Installation von Heartbeat sollten nur die folgenden Schritte ausgeführt werden. Das Repository wird zum Herunterladen mit dem folgenden Befehl installiert:
rpm -ivh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
Bearbeiten Sie die Datei:
epel.repo /etc/yum.repos.d/epel.repo
Ändere Zeile # 6 ‘enable = 1 in enable = 0’; Sie können nach Belieben vi oder nano Editoren verwenden.
[epel] name = Zusätzliche Pakete für Enterprise Linux 6 - $ basearch # baseurl = http: //download.fedoraproject.org/pub/epel/6/$basearch mirrorlist = http: //mirrors.fedoraproject.org/metalink? repo = epel-6 & arch = $ basearch Failovermethode = Priorität enabled = 0 # Dies ist die Zeile, die wir bearbeiten müssen Installieren Sie den Heartbeat mit dem folgenden Befehl: yum -enablerepo = epel install heartbeat Sobald die Installation abgeschlossen ist, wird Folgendes angezeigt: Installiert: heartbeat.i686 0: 3.0.4-1.el6 Vollständig!
Nach Abschluss des Installationsvorgangs müssen die drei für die Heartbeat-Operation wesentlichen Dateien bearbeitet werden. befindet sich in /etc/ha.d
- Authkeys
- ha.cf
- Hasenquellen
Wir öffnen die Datei authkeys mit folgendem Befehl:
vi /etc/ha.d/authkeys
Die folgenden Zeilen werden hinzugefügt:
auth 1 1 sha1 claveparaconexionentreheartbeats # In dieser Zeile definieren wir, was der Schlüssel sein soll, damit der Heartbeat jedes Knotens miteinander kommunizieren kann. Er kann derselbe sein, der in den verschiedenen Drbd- oder Drbd-Befehlen verwendet wird.
Wir ändern die Berechtigungen der authkeys- Datei so, dass sie nur vom root gelesen werden kann:
chmod 600 /etc/ha.d/authkeys
Nun bearbeiten wir die zweite Datei:
vi /etc/ha.d/ha.cf
Wir fügen folgende Zeilen hinzu:
Das Systemprotokoll logfile / var / log / ha-log # ist für zukünftige Rs aktiviert logfacility local0 Keepalive 2 Deadtime 30 # Das System wartet 30 Sekunden, um Node1 für inoperabel zu erklären initdead 120 # Das System wartet am Anfang des Knotens 120 Sekunden, um auf den anderen zu warten. bcast eth0 # Ist die Ethernet-Karte angegeben, über die die Kommunikation zwischen Servern übertragen wird, ist es sehr wichtig zu beachten, da hier definiert wird, welche Netzwerkkarte zum lokalen Netzwerk und welche zur direkten Synchronisation gehört udpport 694 # Der Synchronisationsport ist angegeben, genauso wie in der DRBD können wir mehrere Server und jedes Paar mit seinem jeweils definierten Port haben auto_failback off # Wenn wir es als aus markieren, verhindern wir, dass der Knoten1, der einmal beschädigt und degradiert ist, als primär zurückkehrt oder versucht, zurückzukehren, wodurch ein Konflikt mit einem anderen Knoten entsteht knoten knoten1 knoten2 # wir geben die namen beider knoten an.

Um die Konfiguration abzuschließen, müssen wir die Haresources-Datei mit dem folgenden Befehl bearbeiten:
vi /etc/ha.d/haresources
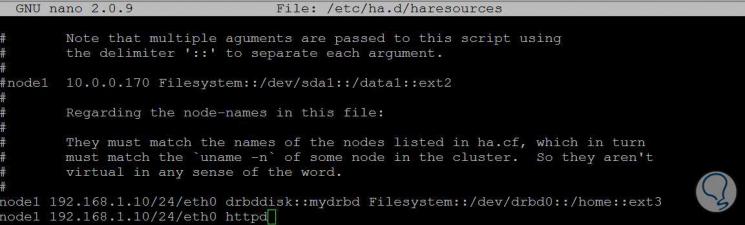
Fügen Sie die folgenden Zeilen hinzu:
node1 192.168.1.10/24/eth0 drbddisk :: mydrbd Dateisystem :: / dev / drbd0 :: / home :: ext3 # Diese Zeile ist für das Mounten der Datenpartition auf dem als primär bezeichneten Knoten verantwortlich node1 192.168.1.10/24/eth0 httpd # Diese Zeile ist für die Definition des Dienstes des Apache- oder Webservers für den als primär bezeichneten Knoten verantwortlich
Die 3 Dateien müssen nach node2 kopiert werden, der folgende Befehl erledigt das:
scp -r /etc/ha.d/root@node2:/etc/
Die Datei httpd.conf muss so bearbeitet werden, dass sie die Anforderungen der virtuellen IP abhört, in diesem Fall die Datei 192.168.1.10:
vi /etc/httpd/conf/httpd.conf
Die Zeile Listen 192.168.1.10:80 wurde hinzugefügt oder geändert
Die geänderte Datei wird auf den zweiten Server kopiert:
scp /etc/httpd/conf/httpd.conf root @ node2: / etc / httpd / conf /
Wir starten den Heartbeat-Service in beiden Knoten:
/etc/init.d/heartbeat start
Damit haben wir unseren Hochverfügbarkeitsserver bereit, es genügt, unseren Internetbrowser aufzurufen und die IP 192.168.1.10 einzutragen oder ein Panel Ihrer Wahl für die Domainverwaltung zu installieren und die entsprechenden Benutzer für den Zugriff auf die zu generieren Seiten oder Domänen, die auf dem Server registriert sind.
Der Hochverfügbarkeitsserver kann wie eingangs erwähnt verwendet werden als: E-Mail-Server, Webserver, Datenbankserver , Samba-Server ua; Es hilft uns auch, den Verlust von Informationen aufgrund von Hardwarefehlern zu verhindern, und wir können ihn durch Überfälle auf die Festplattenlaufwerke, entweder durch Hardware oder Software, noch verstärken. Es ist nie erforderlich, Festplattenlaufwerke zu haben, um das System zu warten.
Der Hochverfügbarkeitsserver ist jedoch nicht frei von Problemen oder Fehlern. Wenn ein Knoten beeinträchtigt ist, können Sie im Heartbeat-Protokoll nachsehen, was passiert ist. Dies wird durch Zugriff auf die Datei erreicht, die in der Konfiguration von Haresources in / etc / zugewiesen wurde. ha.d
Ebenso kann es vorkommen, dass beide Server beim Neustart aus irgendeinem Grund nicht als primär / sekundär und als primär / nicht bekannt und nicht bekannt / sekundär gestartet werden.

Um dies zu lösen, müssen wir die folgenden Schritte ausführen.
In der Shell des abgefallenen Knotens geben wir ein:
drbdadm sekundäre Ressource
Anschließend:
Drbdadm trennen Ressource
Und nachher:
drbdadm - --discard-my-data connect resource
Schließlich geben wir im überlebenden Knoten oder Primärknoten Folgendes ein:
Drbdadm verbinden Ressource
Jetzt wird die Neusynchronisation der Knoten vom überlebenden Knoten zum abgefallenen Knoten gestartet, und zwar sofort, wenn in Anweisung 4 die Eingabetaste gedrückt wird.
Was hier geschah, wird als Split-Brain bezeichnet . Dies geschieht, wenn der Primärknoten aus irgendeinem Grund ausfällt und degradiert ist. In diesem Fall ist es sehr ratsam, den ausgefallenen Knoten zu überprüfen und zu analysieren, bevor er zum Lösen an den Cluster zurückgegeben wird Bei bestehenden Problemen kann es auch erforderlich sein, das gesamte Betriebssystem dieses Knotens neu zu installieren und es problemlos als sekundäres Element für die Synchronisierung in den Cluster zu integrieren. Wenn dies der Fall ist, ändern Sie es nach der Synchronisierung in primäres.
Abschließend möchte ich die regelmäßige Überprüfung des Clusterzustands hervorheben, von der wir wissen, dass es für eine hohe Leistung immer gut ist, Computerkatastrophen einen Schritt voraus zu sein. Da wir als IT-Personal dafür verantwortlich sind, die Daten des Unternehmens oder der Unternehmen, denen wir angehören, zu pflegen, halte ich es nicht für ratsam, immer eine Sicherungskopie in einer Einheit zu haben, die sich mit den Knoten und damit abwechselt die Informationssicherheit gewährleistet sein.
Installieren und konfigurieren Sie Ubuntu Server
