Der Aspekt, der all dies steuert, ist der Index , der die Verantwortung hat zu wissen, wer, was und wann von allen vorgenommenen Änderungen ist. Deshalb wird nach dem Hinzufügen der verschiedenen Aspekte zu unserem Branchenindex das sogenannte Festschreiben durchgeführt.
Das Ressourcenmanagement, das dies so schnell macht, beruht auf der Tatsache, dass Vergleiche über SHA1 durchgeführt werden. Wenn also die Elemente im Index denselben Hash haben, werden sie nicht weiter in ihre Änderungen vertieft, da sie identisch sind und somit nur nimmt die Dateien, die sich wirklich geändert haben.
Die Art und Weise, wie Commits organisiert sind, ermöglicht es uns, hierarchische Strukturen zu erstellen, die die Gewissheit geben, den Ursprung aller registrierten Änderungen zu ermitteln. Wenn wir also die Best Practices von Git befolgen, gehen wir dank der eindeutigen Bezeichner niemals verloren Einige Funktionen haben ein Problem verursacht, das genau an der Stelle gefunden werden kann, an der es enthalten war.
Das einzigartige und unwiederholbare Commit
Wir haben kommentiert, wie die Commits einen Hash in SHA1 haben, mit dem sie identifiziert werden können. Es stellt sich heraus, dass dieser Hash sie auch eindeutig und unwiederholbar macht. Wenn wir also einen Commit haben und in einem anderen Repository denselben Hash gefunden haben, können wir wissen, dass er derselbe ist begehen
Aus diesem Grund wird das Commit auch als atomar betrachtet, dh als eine einzelne Einheit, die unabhängig den Status vieler Verzeichnisse oder Dateien speichert. Damit können wir das Commit als eine Einheit in unserem Repository bezeichnen und somit jedes einzelne als Element behandeln Das ist einzigartig, obwohl es mit dem vorherigen verwandt ist.
Platzieren des Namens beim Festschreiben
Obwohl der SHA1- Hash als eindeutiger Bezeichner für das Commit dient , kann seine Struktur aus 40 alphanumerischen Zeichen ein Problem darstellen, wenn wir mit einem anderen Entwickler kommunizieren und erläutern möchten, um welches Commit es sich handelt.
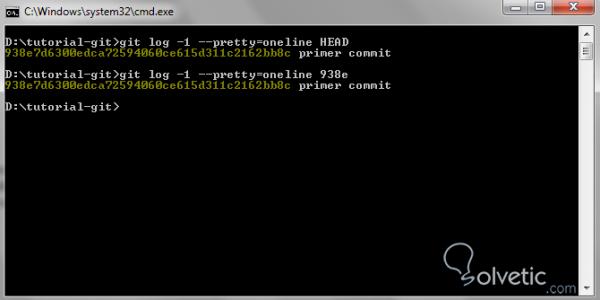
Um über das letzte Festschreiben des Zweigs zu sprechen, können wir einfach auf HEAD verweisen, da dies immer auf das letzte und letzte Festschreiben verweist. Da dies jedoch nicht immer erforderlich ist, ist es ausreichend, dass wir die ersten Zeichen des Hashs verwenden , obwohl dies nicht der Fall ist Dies ist immer eindeutig. Wenn Sie also mehr Zeichen hinzufügen, erhalten Sie die entsprechende Einzigartigkeit.
Schauen wir uns dann den Befehl an, den wir verwenden müssen, um Letzteres zu erreichen:
git log -1 --pretty = oneline identifiercommit
In der folgenden Abbildung sehen wir nun, wie wir ein Commit in unserem Test-Repository identifizieren. Wir suchen zunächst nach dem SHA1 des HEAD und nennen es dann nach den ersten Zeichen.
Git Log, unser Verbündeter Entdecker
Mit dem vorherigen Beispiel haben wir ein Git- Tool entdeckt, das sehr nützlich sein kann und der Befehl log ist. Dies ist sehr leistungsfähig, da es uns ermöglicht, die verschiedenen Commits schnell und präzise zu lokalisieren. Es können jedoch viele Parameter und Konfigurationen verwendet werden es ist zunächst schwierig, sich etwas einprägen zu können, aber um es zu benutzen, müssen wir nicht alle lernen, wir können nach und nach fortfahren, während wir uns an ihren Gebrauch gewöhnen.
Wenn Sie den Verlauf von Commits anzeigen möchten, gehen Sie wie folgt vor:
git log nameBranch
Damit erhalten wir detaillierte Informationen über die Geschichte unserer Branche und ihre Commits . Sehen wir uns an, wie es in unserer Konsole im Test-Repository aussieht:
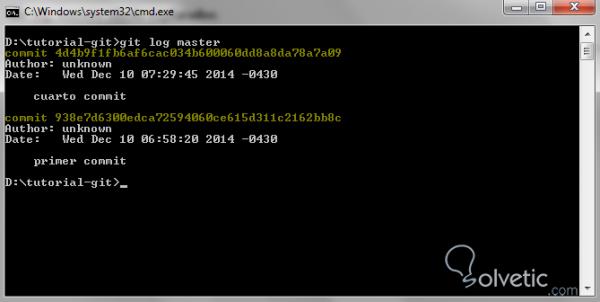
Wir bemerken dann, wie die Commits vom jüngsten bis zum ältesten organisiert sind. Dies ermöglicht es uns, ein wenig die historische Linie der Veränderungen zu sehen, unter denen der ausgewählte Zweig leidet, um das historische Protokoll zu sehen.
Zeichnen Sie die Änderungen
Da das Arbeiten in der Konsole manchmal etwas schwierig ist, obwohl es sehr wichtig ist, bietet Git ein Tool an, mit dem wir den Verlauf von Commits grafisch überprüfen können. Gitk ist kein Unterbefehl von Git wie log, den wir bereits gesehen haben Es ist jedoch ein unabhängiger Befehl, der uns den Zugriff auf weitere Details der Branche und ihrer Geschichte ermöglicht.
Um es zu benutzen, müssen wir einfach den folgenden Befehl ausführen:
gitk nameBranch
Mal sehen, wie die Ausführung in der Konsole aussieht:
Obwohl es den Anschein hat, dass nichts passiert ist, erhalten wir in Kürze ein Fenster mit der gewünschten Grafik für den angegebenen Zweig, wie im folgenden Screenshot zu sehen ist:
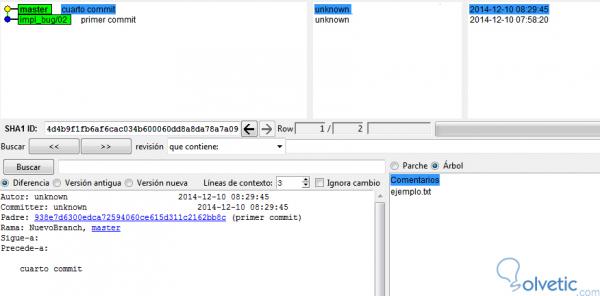
Wir können feststellen, dass wir neben der Verbesserung der Visualisierung ein viel größeres Detail haben.
Refs und Symrefs
Refs und Symrefs entsprechen symbolischen Referenzen bzw. Referenzen , wobei die erste einem SHA1- Bezeichner eines Objekts im Rahmen von Objekten in unserem Repository entspricht, während die zweite indirekt einem Objekt entspricht, obwohl ihr Name auch ein ist Referenz.
Diese Struktur von Referenzen ist sehr wichtig zu wissen, da es uns ermöglicht, die Organisation unseres Verzeichnisses von Commits und Zweigen in Git zu verstehen, die im Verzeichnis .git / ref gespeichert sind .
Lassen Sie uns abschließend sehen, wie die Ausführung dieses Befehls aussieht, wenn wir ihn auf unser Test-Repository anwenden:
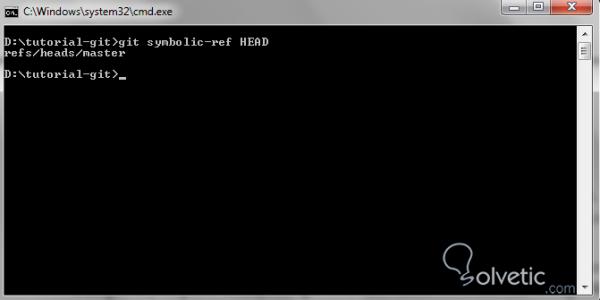
Relative Namen in den Commits
Ein weiterer interessanter Aspekt der Festschreibungen ist, dass wir mit den relativen Namen arbeiten können. Dies macht das Auffinden von Festschreibungsbereichen sehr einfach. Wenn wir beispielsweise herausfinden möchten, was zwischen Überarbeitungen eines bestimmten Zeitraums vorhanden ist, können wir dies tun.
Um dies zu erreichen, müssen wir nur den Filialnamen plus das ^ Symbol und die Revisionsnummer verwenden. Zum Beispiel master ^, wobei wir uns auf die vorletzte Änderung beziehen, die im Zweigmaster vorgenommen wurde.
Ein Beispiel kann master ^ 2 ~ 3 sein , um auf historische Änderungen in unserem Repository zu verweisen. Wenn wir den Namen eines relativen Commits erhalten möchten, müssen wir einfach den folgenden Befehl verwenden:
git rev-parse nombreRelativo
Dies gibt den SHA1 des Commits zurück, zu dem wir gekommen sind. Sehen wir uns in der folgenden Abbildung an, wie wir den Namen des aktuellen Master-Commits und mit master ~ den Namen des ersten übergeordneten Elements desselben Commits abrufen können, mit dem wir begonnen haben:
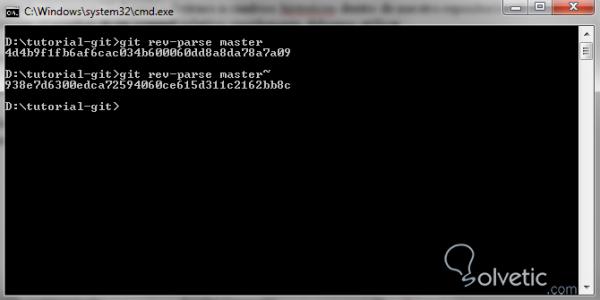
Wir bemerkten dann, wie wir zwei verschiedene und gültige SHA1 in unserem Repository erhalten konnten, wobei nur relative Namen verwendet wurden .
Nachdem wir dieses Tutorial abgeschlossen haben, haben wir neue Konzepte eingeführt, was die Commits in Git darstellen . Dies gibt uns die Möglichkeit, die Strukturen unserer Repositories besser zu verstehen. Dadurch wird die Organisation logischer und wir können viel mehr Wirksam bei Änderungen in unserem Code. Die Art und Weise, wie Git mit den Unterschieden umgeht , macht es zu etwas Besonderem, weshalb es zu einem der Treiber führender Versionen der aktuellen Technologie geworden ist.
