Dies kann nicht weiter von der Realität entfernt sein, trotz des Leistungszuwachses der Geräte sind die Datenbanken von grundlegender Bedeutung für die Leistung der Anwendungen. Aus diesem Grund kann eine gut geschriebene und hochoptimierte Abfrage mehrere Sekunden Ladezeit bedeuten Wenn wir dies mit der Anzahl der gleichzeitigen Benutzer multiplizieren, sehen wir, wie die Kosten und die Energie verschwendet wurden.
Abfragen optimieren
Der beste Weg, um die Leistung unserer Datenbanken zu verbessern, besteht darin, mit gut geschriebenen Abfragen zu beginnen. Oft stellen wir fest, dass die Abfragen nicht gut geschrieben sind, da sie nicht so optimiert sind, wie sie sein sollten. Dafür gibt es viele Gründe. Einer davon ist der Wiederverwendung ohne Codebewusstsein; Damit meinen wir, dass wenn wir irgendwann eine Abfrage machen, die mit einem Left Join funktioniert , wir sie weiterhin anwenden, indem wir die Anzahl der zu konsultierenden Tabellen erhöhen. Wenn Sie sie ändern und einige Klauseln durch einen Inner Join ändern , kann dies den Pfad verkürzen und den Verbrauch von verringern Prozessor.
SQL ist eine Sprache, die zwar leicht zu lesen ist, aber viele Aspekte und Variationen aufweist, die es uns ermöglichen, etwas zu tun, das am besten und schlechtesten funktioniert. Wir müssen jedoch wissen, ob unsere Lösung zu einer Kategorie oder zu einer Kategorie gehört eine andere
Um zu wissen, dass wir auf dem richtigen Weg sind, muss eines der wichtigsten Dinge aktualisiert werden. Das heißt, wir können das Codieren in SQL in PostgreSQL nicht so fortsetzen, als wäre es die erste Version, wenn wir uns in Version 9 befinden .
Über die Verwendung von Unterabfragen
Dies ist einer der häufigsten Fehler, den wir machen, und das heißt, wir stellen uns eine Abfrage als eine Gruppe von Elementen vor, die wir für ein endgültiges Ergebnis vorbereiten. Dieses Verhalten hat jedoch große Auswirkungen auf die Leistung unserer Datenbank.
Sehen wir uns ein Beispiel für dieses typische Verhalten an:
SELECT tract_id , (SELECT COUNT (*) FROM census.facts As F WHERE F.tract_id = T.tract_id) Wie num_facts , (SELECT COUNT (*) FROM census.lu_fact_types As Y WHERE Y.fact_type_id IN (SELECT fact_type_id FROM census.facts F WHERE F.tract_id = T.tract_id)) As num_fact_types FROM census.lu_tracts As T;
Wenn wir nun das EXPLAIN- Diagramm dieser Abfrage sehen, werden wir erkennen, wie teuer es ist, dies auf diese Weise zu tun:
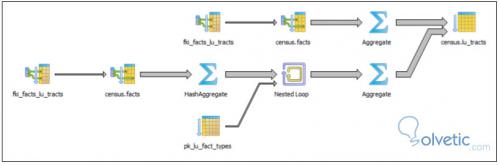
Wie wir sehen, gibt es einige Engpässe in dieser Abfrage, abgesehen von all den Daten, die ineffizient verschoben werden müssen, damit wir sie optimaler umschreiben und mit einer neuen EXPLAIN- Grafik vergleichen können.
SELECT T.tract_id, COUNT (f.fact_type_id) As num_facts, COUNT (DISTINCT fact_type_id) As num_fact_types FROM census.lu_tracts As T LEFT JOIN census.facts As F ON T.tract_id = F.tract_id GROUP BY T.tract_id;
In dieser neuen Version unserer Abfrage vermeiden wir die Verwendung von Unterabfragen. Stattdessen erstellen wir eine Entsprechung mit left join und group by . Wenn wir das Diagramm sehen, können wir den Unterschied erkennen.
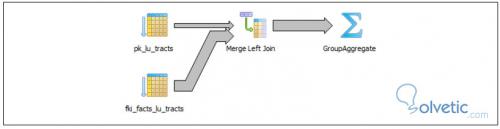
Wir können sehen, dass der Weg, um unser Ergebnis zu erhalten, viel kürzer war, was uns eine höhere Leistung verleiht. Dies bedeutet nicht, dass wir Unterabfragen von unseren Arbeitswerkzeugen ausschließen müssen, aber wir sollten uns dessen bewusst sein, dass sie existieren können Bessere Straßen für das, was wir momentan anheben.
