Die Speicherung in Cassandra ist definiert als ein Schlüssel / Wert, bei dem ein Schlüssel einem oder mehreren Werten zugeordnet werden kann. Es ist eine Datenbank, die sich an Datensätzen nach Zeilen orientiert, wobei jede Zeile durch ihren Schlüssel identifiziert wird und die Besonderheit dieses Systems darin besteht, dass eine Zeile in mehr als einem Knoten gespeichert werden kann.
Architektur von Cassandra
Bevor wir zur Cassandra- Installation in unserem System übergehen, müssen wir etwas über die Architektur dieser Datenbank wissen. Auf diese Weise werden wir wissen, was wir haben und was wir erreichen können.
Replikationsfaktor
Wenn wir über die Replikation von Informationen sprechen, ist eine der ersten Fragen, die wir uns stellen: Wie viele Kopien benötigen wir? Dies ist in Cassandra keine einfache Frage, aber wir müssen berücksichtigen, dass dieser Faktor die Anzahl der Knoten angibt, die in derselben Zeile gespeichert sind.
Ein Replikationsfaktor von 2 garantiert beispielsweise, dass zwei Kopien der Knoteninformationen im Cluster vorhanden sind. Die Auswahl von Wert zwei für den Replikationsfaktor ist gut, um Fehler in einem Knoten in der Entwicklungsumgebung abzudecken, und kann für Produktionsumgebungen minimal sein, da der andere Knoten alle Anforderungen verarbeitet, wenn ein Knoten ausfällt Es ist etwas, das wir sorgfältig überlegen müssen, bevor wir es implementieren.
Das Klatschprotokoll
Das Protokoll, mit dem Cassandra den Standort der Knoten und ihre Informationen im Cluster teilt, heißt Gossip . Wo diese Knoten ständig “murmeln” und Informationen mit bis zu 3 Knoten im Cluster austauschen.
Wie bei anderen Protokollen gibt es auch bei diesem Protokoll Regeln zum Senden von Anforderungen an andere Knoten, für die drei Schritte angezeigt werden. Jeder Knoten wiederholt diese Schritte immer:
– Murmurar a un nodo activo al azar. 1 – Mutter zu einem aktiven Knoten nach dem Zufallsprinzip.
– Iniciar un murmuro hacia un nodo hacia abajo al azar. 2 – Starten Sie ein zufälliges Murmeln in Richtung eines Knotens.
– Este paso es opcional y define que si el nodo seleccionado en el paso uno, no es un nodo semilla, murmurar a otro nodo semilla aleatorio. 3 – Dieser Schritt ist optional und definiert, dass, wenn der in Schritt 1 ausgewählte Knoten kein Startknoten ist, zu einem anderen zufälligen Startknoten gemurmelt wird.
Um die Informationen zu verschieben und die Kommunikation zwischen den Knoten herzustellen, verwendet Cassandra eine Komponente namens Snitch . Schauen wir uns an, was dies bedeutet.
Schnatzkomponente
Grundsätzlich ist diese Komponente für die Verwaltung des Informationsaustauschs zwischen Knoten und anderen Knoten für Abfragen und Replikationen auf der Grundlage verschiedener Metriken verantwortlich. Diese Konfiguration ist für alle Knoten innerhalb des Clusters gleich, sie kann jedoch in ihrem Typ variieren. Sehen wir uns an, was wir zur Verfügung haben:
Cassandra installieren
Die Installation von Cassandra erfolgt auf einem Windows 8-Computer , auf dem wir bestimmte Anforderungen erfüllen müssen. Sehen wir uns an, was wir brauchen:
– Necesitamos tener al menos Java 7 instalado en nuestro sistema, sino lo tenemos podemos descargar la versión más reciente en el siguiente enlace . 1 – Wir müssen mindestens Java 7 in unserem System installiert haben, aber wenn wir es haben, können wir die neueste Version unter dem folgenden Link herunterladen.
– Necesitamos adicionalmente Microsoft Visual C++ 2008 Redistributable Package (x86). 2 – Wir benötigen zusätzlich Microsoft Visual C ++ 2008 Redistributable Package (x86).
– Por último conexión a Internet para poder descargar el paquete de DataStax . 3 – Schließlich Internetverbindung zum Herunterladen des DataStax- Pakets.
Lassen Sie uns nun mit unseren überarbeiteten Anforderungen zur Projektseite gehen und nach der 32- oder 64-Bit-Version suchen, die zu unserem System passt:
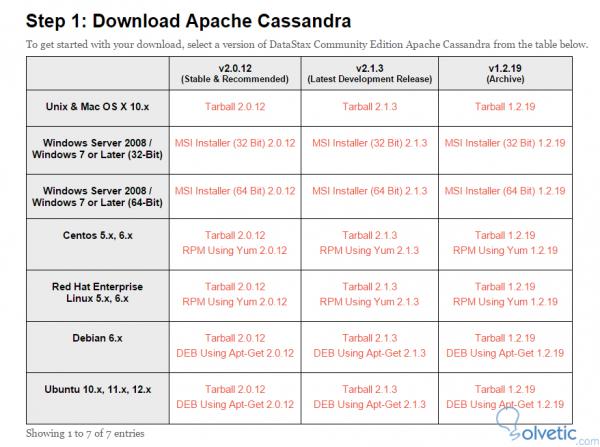
Wenn wir uns Cassandras Konnektivitätsdokumentation mit den verschiedenen Programmiersprachen ansehen möchten, können wir auf der Seite nachsehen, was wir für dieselbe benötigen. Nach dem Download installieren wir wie jede Windows-Anwendung. Wenn es wichtig ist zu erwähnen, dass Cassandra nach dieser Installation standardmäßig einen Cluster von Tests erstellt.
DataStax-Weboberfläche
Bei der Installation werden mehrere Tools in unserem System installiert, eines davon ist das Cassandra -Webinterface namens OpsCenter , in das wir eingeben können, wenn wir in unserem Browser die folgende Adresse eingeben:
http: // localhost: 8888 / opscenter / index.html
Diese Benutzeroberfläche ermöglicht es uns, einige interessante Dinge auszuführen, es ist jedoch nicht die beste, mit Cassandra zu arbeiten, aber für die Zwecke dieses Tutorials ist es wichtig zu wissen, was es bietet, und daher einen Ausgangspunkt zu haben, um die Struktur der zu kennen Datenbank.
Das erste, was wir beim Aufrufen dieser Oberfläche finden, ist der Abschnitt Dashboard , in dem wir verschiedene Leistungsmetriken wie den Zustand des Knotens, die Speicherkapazität oder das Schreiben von Anforderungen visualisieren können:
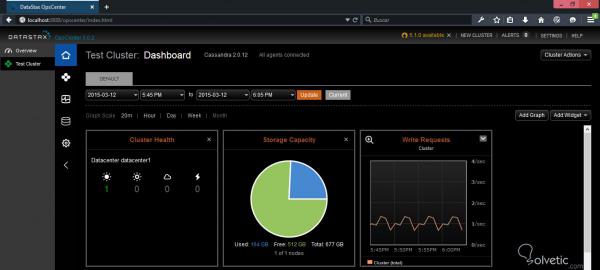
In dieser Oberfläche können wir einen neuen Cluster erstellen. Gehen Sie dazu nach rechts oben und klicken Sie auf Neuer Cluster. Daraufhin wird der folgende Bildschirm geöffnet:
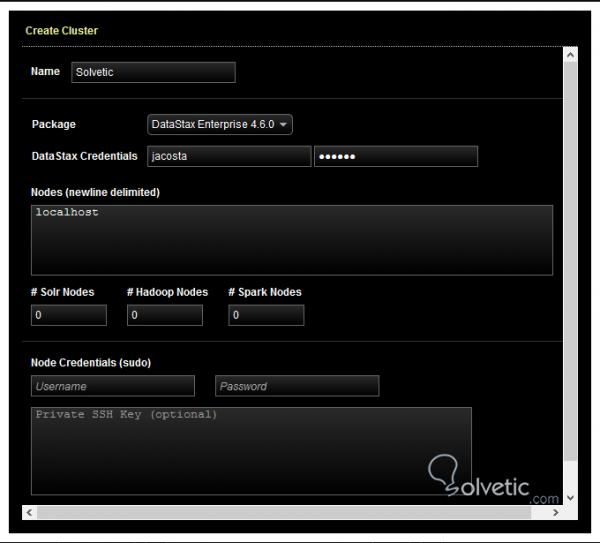
Geben Sie die angeforderten Daten ein und klicken Sie auf ” Cluster erstellen”. Außerdem können Sie in der Dropdown-Liste ” Clusteraktionen” oben rechts Knoten hinzufügen. Im Abschnitt ” Knoten” sehen Sie die verfügbaren Knoten und Rechenzentren sowie bestimmte Parameter wie den Zustand, die Größe der Daten und sogar die generierten Warnungen:
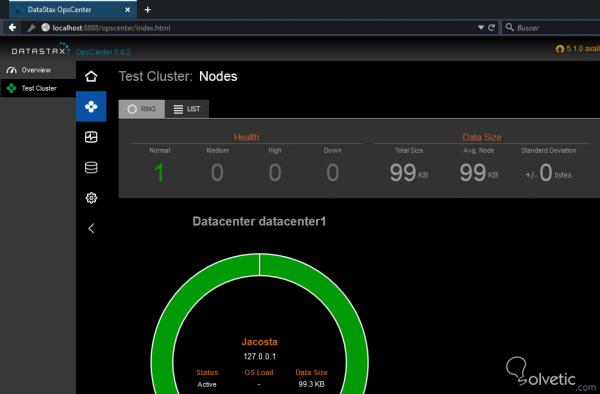
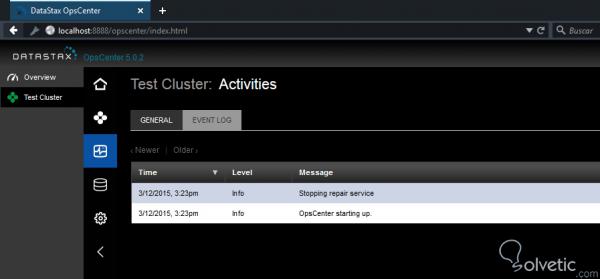
Im Abschnitt ” Aktivitäten ” finden Sie eine Liste der im Cluster ausgeführten Aktivitäten sowie ein Protokoll mit Ereignissen, was für uns als Datenbankadministratoren sehr nützlich ist:
Dann haben wir den wichtigsten Abschnitt in unserer Webschnittstelle, und dies sind Daten . Hier können wir unsere Informationscontainer definieren, die besser als Schlüsselbereiche und die “Tabellen” oder Spaltenfamilien bekannt sind .
Erstellen eines Schlüsselraums und von Spaltenfamilien
Um einen Schlüsselbereich zu erstellen, müssen wir zuerst in den Bereich Daten gehen und dort die Option Hinzufügen auswählen, den Namen, die Replikationsstrategie, die wir erklären können, eine einfache oder Netzwerktopologie, und den Replikationsfaktor eingeben.
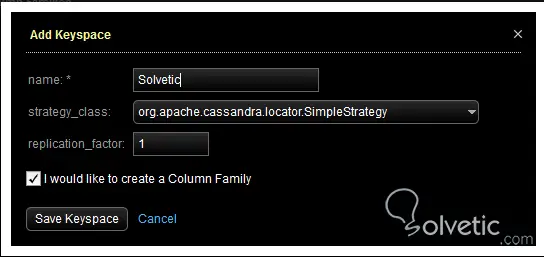
Wir haben gespeichert und hätten unseren Schlüsselbereich erstellt , da wir uns daran erinnern, dass diese Container in Cassandra eine Schlüsselfunktion haben und den Replikationsfaktor definieren sollen. Mit unserem definierten Container fügen wir eine Spaltenfamilie hinzu , geben diese in den Keyspace ein und wählen die Option Hinzufügen . Hier geben wir den Namen, den Spaltentyp und den Komparatortyp ein.
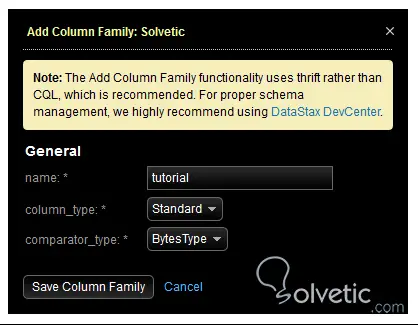
Damit haben wir bereits unsere Spaltenfamilie erstellt , da wir sehen, dass dies sehr einfach ist. Diese Benutzeroberfläche schränkt uns jedoch in vielerlei Hinsicht ein und ist nur ein guter Ausgangspunkt für Anfänger, die verstehen möchten, wie Cassandra strukturiert ist und wie sie die Cluster verwaltet , Knoten, Schlüsselräume und Spaltenfamilien .
Damit haben wir dieses Tutorial abgeschlossen, in dem wir sehen konnten, wie die Cassandra- Architektur, ihr Protokoll, ihre Komponenten und ihre Installation aussehen. Wir kannten die Struktur über das Webinterface, haben aber damit nur die Spitze des Eisbergs berührt. In zukünftigen Tutorials werden wir vollständig mit CQL und der professionellen Arbeitsweise mit Cassandra vertraut sein .
