Git arbeitet auf interessante Art und Weise, um Dateiänderungen im Auge zu behalten. Obwohl es den Anschein haben könnte, dass es nach den Änderungen in jedem dieser Elemente sucht, besteht seine eigentliche Aufgabe darin, eine Datei mit dem Namen index zu erstellen, in die die vorgenommenen Änderungen eingefügt werden. Auf diese Weise können Sie durch Lesen der Indexdatei erkennen, welche Dateien und welcher Inhalt in ihnen geändert wurden.
Sobald wir das Konzept verstanden haben, wie Git die aufgezeichneten Änderungen überträgt, können wir beginnen, das Tool in vollem Umfang zu nutzen, da wir in diesem Moment die verschiedenen Befehle verwenden können, um Änderungen in unser Repository zu übernehmen und sie zu verarbeiten aus einer logischen Perspektive.
Klassifizierung von Dateien innerhalb von Git
Bevor wir mit tieferen Punkten fortfahren, müssen wir sehen, wie Git seine Dateien klassifiziert. Dies bedeutet keine Klassifizierung nach Dateityp aufgrund seiner Erweiterung, wenn nicht nach dem Status desselben in Bezug auf unser Repository und dessen Index .
Grundsätzlich gibt es in GIT drei Dateitypen, von denen jeder seinen eigenen Moment im Repository hat. Sehen wir uns diese an:
git add Dateiname
Praktisches Beispiel für die Dateiklassifizierung
Sehen wir uns nun ein kleines praktisches Beispiel an, wie wir die Dateitypen in einem Git- Repository erkennen können. Dazu müssen wir die folgenden Schritte ausführen:
– Vamos a crear una carpeta nueva en nuestro equipo que se llame archivosGit . 1 – Wir erstellen einen neuen Ordner auf unserem Computer, der Git- Dateien heißt .
– Una vez creada la carpeta vamos a ingresar dentro de ella desde nuestra consola y ahí vamos a ejecutar el comando git init y luego hacemos git status para ver el estado de nuestro repositorio, veamos como luce la aplicación de los comandos anteriores: 2 – Nachdem wir den Ordner erstellt haben, geben wir ihn von unserer Konsole aus ein und führen dort den Befehl git init aus. Anschließend führen wir git status aus , um den Status unseres Repositorys anzuzeigen. Sehen wir uns an, wie die Anwendung der vorherigen Befehle aussieht:
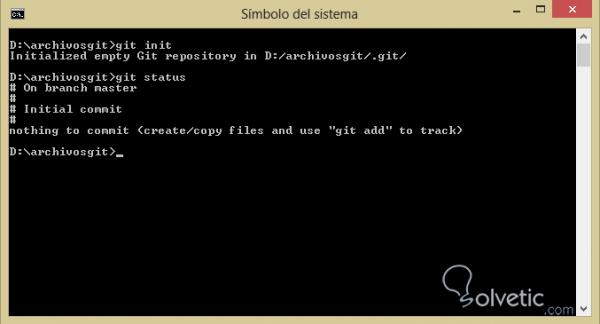
– Cuando hayamos cumplido el paso anterior ya tendremos un repositorio Git inicializado y listo para trabajar, entonces podemos crear un nuevo archivo en esa carpeta y haremos nuevamente git status para ver el cambio, debemos tener nuestro nuevo archivo bajo la clasificación untracked . 3 – Wenn wir den vorherigen Schritt abgeschlossen haben, haben wir ein Git- Repository initialisiert und sind bereit zu arbeiten. Dann können wir eine neue Datei in diesem Ordner erstellen und den Git-Status erneut durchführen, um die Änderung zu sehen. Wir müssen unsere neue Datei unter der nicht verfolgten Klassifizierung haben.
– Vamos a repetir el paso anterior y crearemos un nuevo archivo, si vemos el resultado de hacer nuevamente git status contaremos ambos archivos, veamos: 4 – Wir werden den vorherigen Schritt wiederholen und eine neue Datei erstellen. Wenn wir das Ergebnis eines erneuten Git-Status sehen, werden wir beide Dateien zählen.
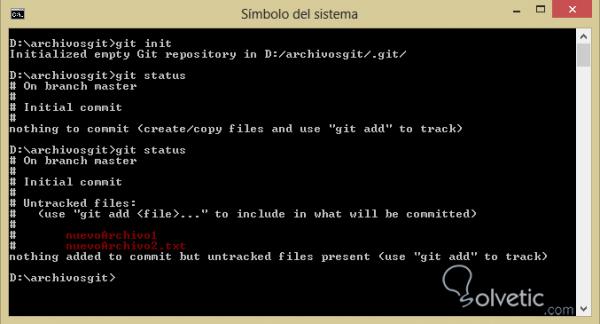
– Ahora vamos a crear un nuevo archivo llamado .gitignore , nótese el punto antes del archivo y dentro vamos a colocar el nombre de uno de nuestros archivos anteriores, hacemos nuevamente git status y veremos que ahora solo nos sale el archivo que no está en él .gitignore y el archivo .gitignore que acabamos de crear: 5 – Jetzt werden wir eine neue Datei mit dem Namen .gitignore erstellen , den Punkt vor der Datei notieren und im Inneren den Namen einer unserer vorherigen Dateien platzieren. Wir führen den Git-Status erneut aus und werden sehen, dass wir nur die Datei erhalten, die nicht in ist ihn .gitignore und die .gitignore- Datei, die wir gerade erstellt haben:
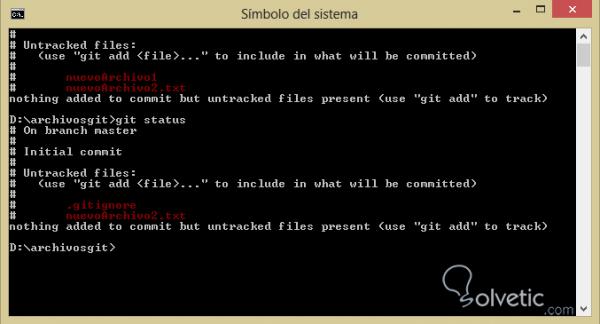
– Luego haremos un git add . 6 – Dann werden wir einen Git hinzufügen. Um alle unsere Dateien hinzuzufügen und schließlich ein git commit -m “initial commit” auszuführen, fügen wir unsere Dateien zum Repository hinzu, wenn wir eine Änderung an der Datei vornehmen, die wir nicht im .gitignore ablegen, und speichern, wenn wir den git status erneut ausführen in eine Datei im Status oder nachverfolgte Klassifizierung.
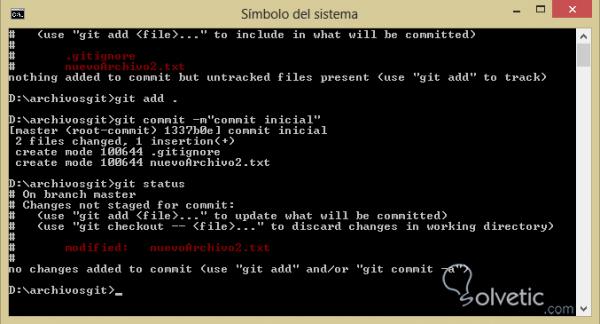
Der Befehl git add
Im vorherigen Beispiel haben wir die Verwendung von git add gesehen und vielleicht können wir annehmen, dass es ein weiterer Befehl unseres Tools ist, aber dies ist von größter Wichtigkeit. Es ist der Befehl, mit dem wir eine Datei zu unserem Repository hinzufügen können, wenn sie noch nicht vorhanden ist, und wir auch Hiermit können Sie die Änderungen hinzufügen, die in einer vorhandenen Datei in unserem Repository vorgenommen wurden.
Es ist sehr wichtig, dass wir nach Änderungen am Repository die Dateien mit git add hinzufügen . Andernfalls können wir unsere Änderungen nicht speichern und verschiedene Versionen der Datei erstellen, was zu einem möglichen Konflikt in der Zukunft führen könnte.
Mit dem Git hinzufügen
In unseren Ordner- Git- Dateien , die wir im vorherigen Tutorial-Beispiel erstellt haben, fügen wir eine neue Datei hinzu, die wir in newFile3 platzieren und dann in die vorhandene Datei, die nicht darin enthalten ist .
Damit möchten wir testen, wie unser Befehl git add verwendet wird. Sehen wir uns an, wie er in unserer Befehlskonsole aussieht:
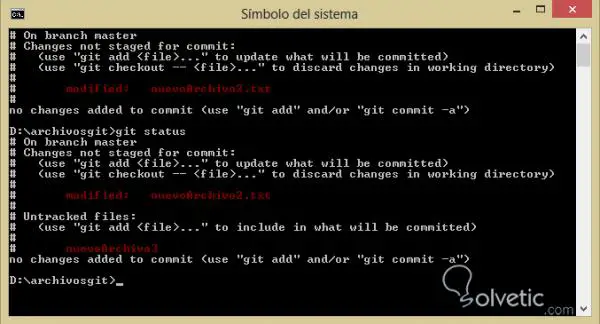
Nachdem wir die obigen Anweisungen befolgt haben, müssen wir etwas Ähnliches wie die vorherige auf dem Bildschirm haben, wo uns eine geänderte Datei und eine völlig neue Datei im Repository angezeigt werden.
Jetzt werden wir die neue Datei zum Repository hinzufügen, aber wir werden es nicht mit der vorhandenen Datei oder der zuvor geänderten Datei tun. Dazu müssen wir nur den Namen unserer Datei hinzufügen . Dann machen wir Git Status . Mal sehen:
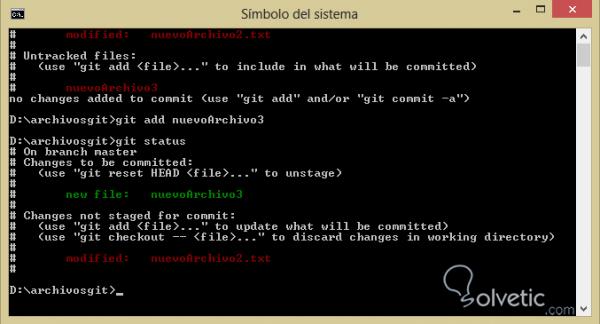
Wie wir bereits feststellen können, berücksichtigt unser Repository die Datei, die wir mit git add hinzugefügt haben. Auf diese Weise können wir im Grunde genommen die Änderungen unserer Dateien bearbeiten.
Löschen Sie Dateien aus dem Repository
Die nächste Aktion, die wir ausführen sollten, besteht darin, die Dateien aus unserem Repository zu entfernen, da es sehr häufig vorkommt, dass wir versehentlich etwas erstellt haben oder einfach Dinge in Ordnung bringen.
Es gibt zwei Dinge zu beachten, wir können die Indexdatei aus unserem Repository löschen, aber diese Datei im System unseres Ordners behalten. Wenn wir also einen Git-Status haben, werden wir sehen, dass sie wieder verfügbar ist. Oder wenn wir die Datei nicht sowohl aus unserem Ordner als auch aus dem Index unseres Repositorys löschen können, können wir dafür den Befehl git rm verwenden .
Der Befehl git rm – -cached
Wenn Sie den Befehl rm mit der hinzugefügten Option cached verwenden , löschen Sie die betreffende Datei aus dem Index . Wir behalten sie jedoch in unserem Team. Dieser Befehl wird häufig verwendet, wenn wir diese Datei nicht zu unserem Repository hinzufügen, sondern speichern müssen die anderen Änderungen.
Um es zu benutzen, machen wir einfach den Befehl, wenn wir bereits eine Datei mit git add hinzugefügt haben. Schauen wir uns an, wie es in unserer Kommandokonsole aussieht:
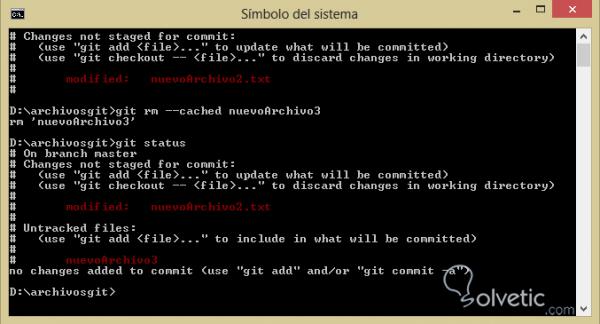
Wir haben festgestellt, dass die neue Datei File3 , die wir jetzt zu unserem Repository hinzugefügt haben, nicht die nicht verfolgte Klassifizierung hat.
Der Befehl Git rm
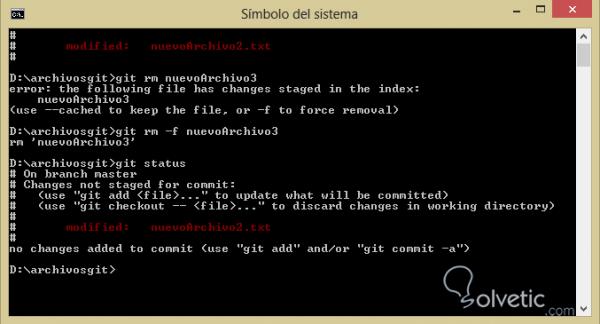
Lassen Sie uns nun sehen, wie der Befehl git rm verwendet wird. Dieser Befehl ist viel leistungsfähiger, da er die Datei direkt aus dem Index und aus dem Ordner entfernt . Deshalb müssen wir vorsichtig sein, wenn wir ihn in unserem Repository verwenden, es ist sehr wahrscheinlich Einmal angewendet, können wir die Änderung nicht wiederherstellen.
In dem folgenden Beispiel sehen wir, wie es funktioniert, wenn wir es auf eine Datei anwenden. In diesem Fall werden wir mit git add eine neue Datei 3 hinzufügen und dann auf diese git rm anwenden:
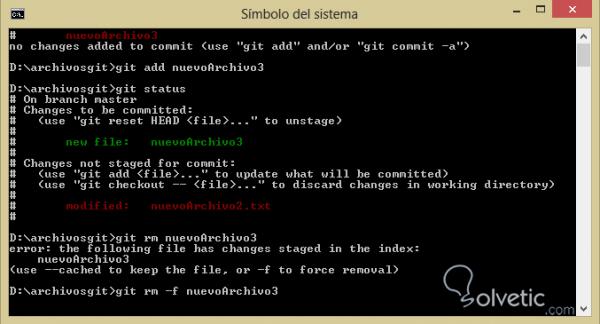
Wir sehen, dass wenn wir es direkt tun, git uns einen Fehler anzeigt und uns auffordert, eine erzwungene Löschung durchzuführen, wenn der Parameter -f zum Befehl hinzugefügt wird. Dies liegt an der Wichtigkeit der Änderung. Schließlich werden wir einen git-Status ausführen und feststellen, dass diese Datei aus unserem verschwunden ist Repository in seiner Gesamtheit.
Mehr von .gitignore
Wir konnten feststellen, dass wir unserer .gitignore- Datei eine bestimmte Datei hinzufügen können. Wenn wir jedoch in einer Umgebung arbeiten, in der Hunderte oder vielleicht Tausende von Dateien verarbeitet werden, ist dies nicht sehr praktisch. Aus diesem Grund können wir Muster verwenden.
Mithilfe eines Musters können wir Git mitteilen, dass eine Datei, die der Zeichen- oder Ausdrucksfolge entspricht, ignoriert werden soll. Dabei können wir bestimmte Erweiterungen entweder im gesamten Projekt oder in einem bestimmten Ordner angeben. Sehen wir uns ein Beispiel dafür an.
* .jpg ignoriert alle .jpg-Dateien unseres Projekts, aber wenn wir die Spur einer bestimmten behalten möchten, sollten wir nur hinzufügen:
! nombrearchivo.jpg
Es ist so einfach, dass wir eine starke und komplexe Struktur haben, die es uns ermöglicht, unser Repository organisiert zu halten.
Nachdem wir dieses Tutorial fertiggestellt haben, haben wir in umfassender Weise gesehen, wie Git die Änderungen in unseren Dateien übernimmt oder handhabt. Es ist wichtig, dieses Thema zu beherrschen, da wir damit effizienter in Teamumgebungen arbeiten können, in denen Git verwaltet wird. als Versionstreiber.