Heute werde ich Ihnen beibringen, wie Sie mit Python ( Web Scraping ) durch die Links einer Seite gehen. Dies kann sehr nützlich sein, um Inhalte in einem Web automatisch zu verfolgen und muss dies nicht manuell tun. In dem Programm, das ich Ihnen durch Lesen des HTML-Codes bringe, können Sie das Programm so ändern, dass es nach Inhalten sucht und nur die Links anzeigt, an denen Sie interessiert sind.
Sie können Web-Scraping auch mit der Datei robots.txt oder den Sitemaps der Websites durchführen.
Dann lasse ich den Code:
Importwarteschlange import urllib.request Import wieder aus urllib.parse importieren urljoin def download (Seite): versuche: request = urllib.request.Request (Seite) html = urllib.request.urlopen (request) .read () drucken ("[*] Download OK >>", Seite) außer: print ('[!] Fehler beim Herunterladen', Seite) return Keine HTML zurückgeben def crawlLinks (Seite): searchLinks = re.compile ('<a [^>] + href = ["'] (. *?) [" ']', re.IGNORECASE) tail = queue.Queue () cola.put (Seite) visited = [Seite] drucken ("Suche nach Links in", Seite) while (cola.qsize ()> 0): html = download (cola.get ()) if html == None: weiter links = searchLinks.findall (str (html)) für link in links: link = urljoin (Seite, str (link)) if (Link nicht besucht): cola.put (link) visited.append (link) if __name__ == "__main__": crawlLinks ("http://www.solvetic.com")
Das erste, was wir tun, ist, die erforderlichen Bibliotheken zu importieren , um die regulären Ausdrücke (re), die Warteschlange zu verwenden, Anforderungen zu stellen und eine Seite (urllib.request) zu lesen und absolute URLs aus a zu erstellen Basis-URL und andere URL (URL).
- Wir erstellen eine Variable mit einem regulären Ausdruck, der uns hilft, die Links im HTML zu finden.
- Wir beginnen eine Variable vom Typ Warteschlange mit der ersten Seite. Dies hilft uns, die Links in der Reihenfolge zu halten, in der wir sie entdecken. Wir initiieren auch eine Variable namens “Besuchslistentyp”, mit der wir die Links speichern, während sie besucht werden. Dies geschieht, um eine Endlosschleife zu vermeiden. Stellen Sie sich vor, dass die Seite x auf die Seite und verweist, und dies wiederum auf die Seite x wir werden diese links die ganze zeit ohne ende einfügen.
- Der Kern der Funktion ist die while-Schleife, die ausgeführt wird, solange die Warteschlange über Links verfügt. Wir überprüfen daher, ob die Größe größer als 0 ist. In jedem Durchgang entfernen wir einen Link aus der Warteschlange und senden ihn an die Download-Funktion. Das HTML wird an uns zurückgesendet, dann suchen wir nach den Links und prüfen, ob wir es bereits besucht haben. Wenn nicht, fügen wir es der Warteschlange und der Liste hinzu.
Der letzte Teil des Codes, der sich bereits außerhalb der Funktionen befindet, ist für die Ausführung des Codes verantwortlich. In der folgenden Abbildung sehen Sie eine Erfassung des laufenden Codes, der bis TechnoWikis verfolgt wird.
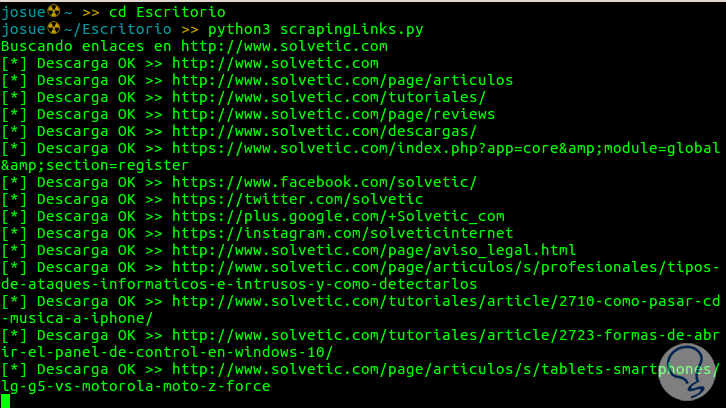
Wenn Sie möchten, können Sie aus einer für Python vorhandenen Bibliothek namens BeautifulSoup heraushelfen , die sehr einfach zu verwalten zu sein scheint. Ich empfehle sie.
Falls Sie den Code möchten, finden Sie hier eine Zip:
 237 Descargas BrowseLinks.zip 646 Bytes 237 Downloads
237 Descargas BrowseLinks.zip 646 Bytes 237 Downloads