Wenn sich R shines in der Erstellung von Diagrammen befindet, bevor der statistische Prozess beginnt, ist dies sehr nützlich, um einzelne Variablen auswerten zu können, die mehrere Faktoren sichtbar machen Analyse bis zur Auswertung von Mustern darin.
Balkendiagramme für kategoriale Variablen
Der einfachste Weg, um mit der Erstellung von Diagrammen in R zu beginnen, besteht in der Verwendung von kategorialen Variablen. Dies können die ***** eines Mitarbeiters oder sogar der Sektor eines bestimmten Unternehmens sein, um nur einige zu nennen. Die Balkendiagramme funktionieren mit dieser Art von Variablen recht gut, und deshalb werden wir mit diesen beginnen.
el cual está incluido en el paquete de datasets y registra el peso de gallinas y la comida que han recibido , este contiene 71 clases y para ver toda la información referente al mismo podemos ejecutar el comando ?chickwts y nos debería desplegar una pantalla como vemos en la sección derecha de la siguiente imagen: Die beste Methode, um zu sehen, wie diese Funktion in R funktioniert, ist ein einfaches Beispiel, in dem wir den Datensatz chickwts verwenden, der im Datensatzpaket enthalten ist und das Gewicht der Hühner und des erhaltenen Futters aufzeichnet. Er enthält 71 Klassen und um alle Informationen darüber zu sehen, können wir den Befehl ? chickwts ausführen und wir sollten einen Bildschirm anzeigen, wie wir ihn im rechten Abschnitt des folgenden Bildes sehen:
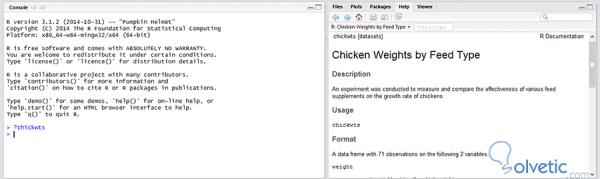
Nachdem Sie die Informationen des Datensatzes bereits gelesen haben, ist es an der Zeit, diese kategorialen Variablen grafisch darzustellen. Dazu müssen Sie zunächst das Datensatzpaket einschließen :
# lade die Informationen der Packagerequire ("Datasets")
Und dann übergeben wir mit der Funktion plot () die Feed- Variable des Datensatzes chickwts:
# Diagramm standardmäßig mit der plot () - Plotmethode (chickwts $ feed)
Beim Ausführen der letzten Befehlszeile sollte die folgende Grafik in unserer Informationsausgabeschnittstelle angezeigt werden:
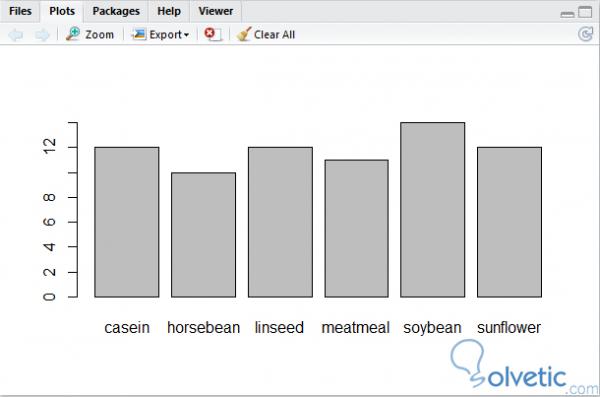
Es ist wichtig zu erwähnen, dass die plot () – Funktion anpassbar ist, das heißt, dass sie abhängig von der übergebenen Variablen verschiedene Arten von Grafiken erzeugt, in diesem Beispiel, als wir eine kategoriale Variable übergaben, wurde ein Balkendiagramm erzeugt Mit plot () können Sie das Diagramm nicht umfassend steuern, z. B. Titel hinzufügen, Balken neu anordnen oder Ränder ändern, um nur einige zu nennen.
Hierfür haben wir eine Alternative und die Funktion barplot (), die uns mehr Kontrolle über den Graphen gibt. Dazu müssen wir die Häufigkeiten für den Graphen mithilfe der Funktionstabelle () berechnen. Sehen wir uns Folgendes an:
# Erstellen der Tabellenfeeds <- Tabelle (chickwts $ feed) Feeds Barplot (Feeds)
Sobald dies erledigt ist, können wir unser Diagramm mit barplot () erstellen, wir werden einige Parameter mit der Funktion par () hinzufügen, mit der wir die Ränder unseres Diagramms ändern und mit unserer Hauptfunktion werden wir die Ausrichtung der Balken ändern, wir werden die Farbe derselben ändern und wir werden hinzufügen Einen Haupttitel und die Beschriftungen für die x-Achse sehen wir uns den Code an:
par (oma = c (1, 4, 1, 1)) par (mar = c (4, 5, 2, 1)) Barplot (Feeds [***** (Feeds)], horiz = TRUE, las = 1, col = c ("network", "red1", "red2", "red3", "red4", "maroon"), border = NA, main = "Häufigkeiten verschiedener Arten von Lebensmitteln", xlab = " Anzahl der Hühner ")
Wenn wir unser Programm ausführen, sollten wir etwas sehen, das dem folgenden Bild ähnlich ist:
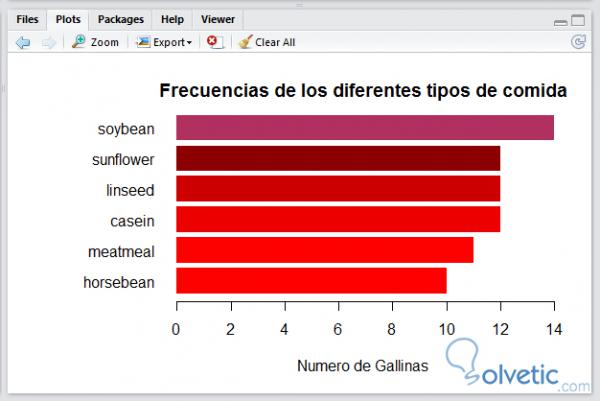
Schließlich verwenden wir den folgenden Code, um die Parameter des Diagramms zurückzusetzen und den Arbeitsbereich von Variablen, Objekten und Paketen zu reinigen, die wir nicht benötigen:
par (oldpar) detach ("package: datasets", unload = TRUE) rm (list = ls ())
Wie diese Art der Analyse in einem Team durchgeführt wird, ist wichtig, um Informationen schnell und einfach auszutauschen. Deshalb kann RStudio unsere Grafiken als Bild oder PDF exportieren. Dazu gehen wir zum oberen Menü und Wir wählen Diagramme oder Grafiken aus. Im folgenden Bild können wir sehen, wie das Ausgabeformat aussieht, wenn wir Als Bild speichern auswählen:
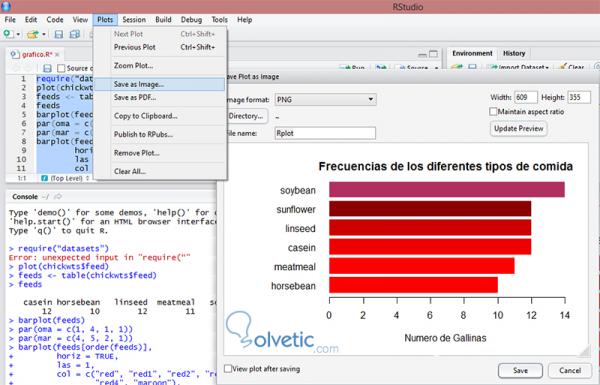
Wir wählen die Route aus, auf der unser Bild gespeichert werden soll, wir geben ihm einen Namen und wenn wir möchten, können wir dessen Breite und Höhe ändern, wir drücken auf Speichern und wir haben unsere Grafik in einem Format, das wir problemlos teilen können.
Kuchendiagramm
Eine weitere Option, die wir zur Darstellung der kategorialen Variablen benötigen , sind Tortendiagramme . Diese Diagramme sind etwas unzulänglich in der Art und Weise, wie sie Informationen darstellen, da das Auge lineare Maße und keine relativen Bereiche gut beurteilen kann. In diesem Tutorial werden wir erklären, wie man sie macht. Wir empfehlen jedoch, ihre Verwendung zu vermeiden, es sei denn, dies ist eine Anforderung des Projekts, das wir gerade durchführen.
Der Aufbau der Kuchengrafiken ist dem Balken ziemlich ähnlich. Zuerst müssen wir das Datensatzpaket einbeziehen, die Häufigkeit für den Graphen berechnen und mit der foot () -Funktion die Optionen steuern. Verwenden Sie den chickwts- Datensatz, um seine Verwendung zu demonstrieren:
require ("datasets") feeds <- table (chickwts $ feed) feedspie (feeds) foot (feeds [***** (feeds, absteigend = TRUE)], init.angle = 90, im uhrzeigersinn = TRUE, col = c ("seashell", "cadetblue2", "orange", "lightcyan", "maroon", "beige"), main = "Grafik von Kuchenmehlhühnern")
Wie wir sehen können, ist die Konstruktion ziemlich ähnlich, wir können die Farben für die Grafik sowie den Titel definieren, wenn wir es ausführen, wollen wir sehen, wie es aussieht:
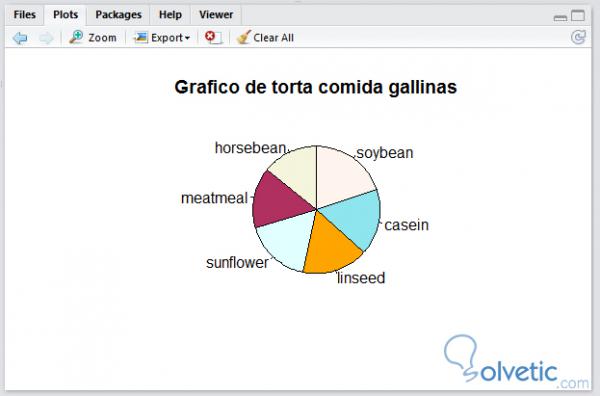
Histogramme
Ein Histogramm ist eine Variation eines Balkendiagramms, mit dem ein Panorama einer bestimmten Population oder eine Stichprobe gemäß einer quantitativen Eigenschaft erstellt werden kann. Zum Beispiel ist die Temperatur in Fahrenheit eine Intervallvariable, da man sagen kann, dass die Temperatur für heute 2,4 Grad höher ist als gestern.
Um ein Histogramm zu erstellen, ist es wichtig zu wissen, wie weit unsere Messungen sind. Variablen wie Temperatur oder Entfernungen haben Werte, die bei Null beginnen. Diese Variablen können für die Histogramme verwendet werden.
Da R bereits einen Satz vorbestimmter Daten für jeden Diagrammtyp hat, den wir finden können, verwenden wir den Luchs- Datensatz, der eine Reihe von Informationen enthält. Wir schließen das Datensatzpaket ein und verwenden die data () -Funktionen zum Initialisieren die Variable und dann mit hist () zeichnen wir unser Histogramm, sehen wir uns den Code:
erfordern ("Datensätze") Daten (Luchs) Hist (Luchs)
Bei der Ausführung erhalten wir Folgendes:
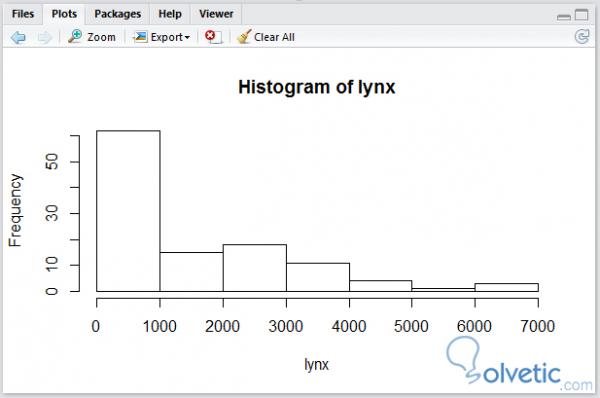
Da wir ein Histogramm in R sehen können, ist es recht einfach zu lesen, nur mit den Standardoptionen, aber wie bei den vorherigen Funktionen können wir einige Optionen unseres Diagramms steuern, wir werden der Funktion hist () einige Optionen hinzufügen Wie ist unser Code mit den Modifikationen:
Require ("datasets") data (lynx) hist (lynx, breaks = 14, freq = FALSE, col = "maroon", main = "Histogramm des gefangenen Luchses", xlab = "Numbers of lynx trapped")
Mal sehen, wie unser Histogramm nach der Ausführung aussieht:
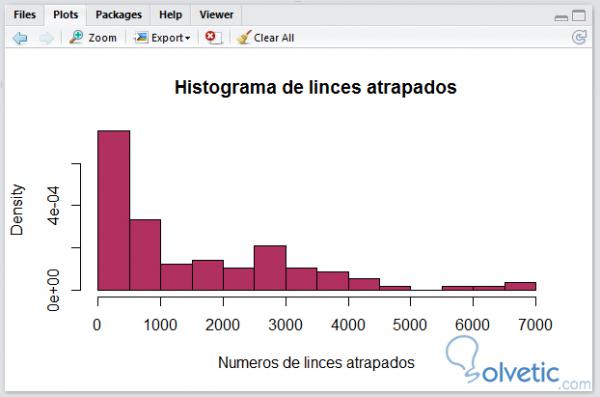
Wie wir sehen konnten, können Sie die Optionen unserer Tabelle problemlos ändern. Mit den Histogrammen in R können wir einen anderen Grafiktyp hinzufügen, um die Funktionalität und den Detaillierungsgrad zu erhöhen. Im nächsten Beispiel werden wir vier verschiedene Grafiktypen hinzufügen, zunächst eine Kurve zur Darstellung einer Normalverteilung und zwei Dichtekurven Im Kernel und in einem linearen Diagramm sehen wir uns an, wie unser Code aussieht, wenn wir die folgenden Funktionen hinzufügen:
erfordern ("datensätze") daten (luchs) hist (luchs, pausen = 14, freq = FALSE, col = "kastanienbraun", main = "histogramm des luchses gefangen", xlab = "zahlen des luchses gefangen") curve (dnorm ( x, Mittelwert = Mittelwert (Luchs), sd = sd (Luchs)), col = "Distel4", unzüchtig = 2, add = WAHR) Linien (Dichte (Luchs), col = "blau", lwd = 2) Linien ( Dichte (Luchs, anpassen = 3), Farbe = "dunkelgrün", LWD = 2) Teppich (Luchs, LWD = 2)
Wie wir sehen, ist es ganz einfach, diese zusätzlichen Grafiken hinzuzufügen, um unser Histogramm detaillierter zu gestalten. Verwenden Sie dazu die Funktionen curve (), lines () und rug (), um zu sehen, wie unser Histogramm mit diesen neuen Optionen aussieht:
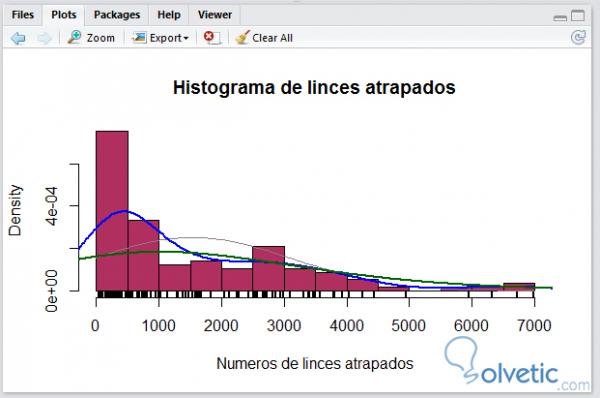
Box-Diagramm
Ein Kastendiagramm basiert hauptsächlich auf Quartilen, die nichts anderes als eine Aufteilung der geordneten Daten sind. Mit diesem Diagramm können Sie diese Daten visualisieren und Informationen über das gesamte Spektrum bereitstellen, das sie enthält.
Die Erstellung eines Box-Diagramms ist recht einfach. Hierfür verwenden wir wieder das Lynx-Dataset. Sehen wir uns einen einfachen Code für dessen Verwendung an:
erfordern ("Datensätze") Daten (Luchs) Boxplot (Luchs)
Wenn wir unser Programm ausführen, sollten wir das folgende Ergebnis erhalten:
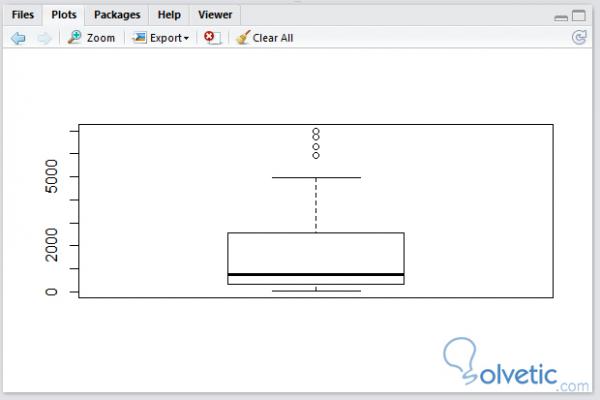
Die boxplot () -Funktion ermöglicht es uns auch, die Kontrolle über unser Diagramm zu erlangen und seine grundlegenden Optionen zu ändern, indem wir das Cashflow-Diagramm detaillierter darstellen. Sehen wir uns an, wie unser Programm mit zusätzlichen Optionen aussieht:
erfordern ("datensätze") daten (luchs) boxplot (luchs, horizontal = WAHR, las = 1, notch = WAHR, col = "kastanienbraun", boxwex = 0,5, whisklty = 1, staplelty = 0, outpch = 16, outcol = "maroon", main = "Histogramm des gefangenen Luchses", xlab = "Anzahl der gefangenen Luchse")
Dieses Boxdiagramm, das für die Darstellung verantwortlich ist, ist die Symmetrie zwischen der Verteilung, wichtige Information für die statistische Analyse, die wir in zukünftigen Tutorials sehen werden.
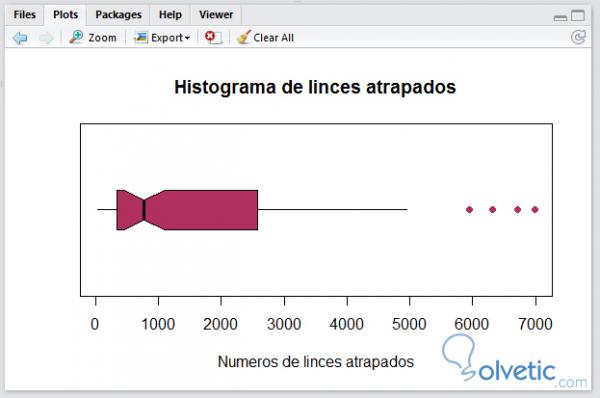
Damit beenden wir dieses Tutorial, mit dem wir einen weiteren Vorteil von R , seinen vollständigen und umfangreichen Datenbeständen sowie den Funktionen zur grafischen Darstellung von kategorialen Variablen kennenlernen. Dies ist ein grundlegender Prozess, den wir für die statistische Analyse von R beherrschen müssen unsere Daten