Die Datenbanken sind aufgrund ihrer Dynamik, Hierarchie, Parameterkonfiguration und einfachen Verwaltung ein grundlegendes Element bei der Arbeit mit großen Datenmengen.
Heute haben wir die Möglichkeit, verschiedene Datenbanken wie MySQL, MariaDB usw. auszuwählen, und jede hat ihre Vorteile und ihre Anpassungen, die auf der Anzahl der Benutzer und den zu verwendenden Parametern basieren. Heute werden wir uns jedoch mit einer speziellen Datenbank namens Cassandra la befassen Dies kann sehr nützlich sein, wenn Sie mit Datenbanken arbeiten, und dafür werden wir CentOS 7 verwenden.
Cassandra verfügt über Faktoren wie lineare Skalierbarkeit und Fehlertoleranz bei der grundlegenden Hardware oder Infrastruktur in der Cloud, die es zur perfekten Plattform für geschäftskritische Daten machen. Die Unterstützung von Cassandra für die Replikation in mehreren Rechenzentren ist die beste ihrer Kategorie, die eine geringere Latenz für Benutzer gewährleistet, indem die Gesamtleistung verbessert wird.
Cassandra ist eine Datenbank, die die lokale Replikation und Replikation mehrerer Rechenzentren für Redundanz, Failover und Disaster Recovery unterstützt .
- Verfügbarkeit: Die Cassandra-Datenbank ist für ihre Zuverlässigkeit bis zu dem Punkt bekannt, dass sie von mehr als 1000 Unternehmen weltweit verwendet wird. Darunter können wir Instagram, GitHub und Netflix hervorheben, mit denen wir Cassandra in vollem Umfang nutzen können.
- Fehlertoleranz: Ein kritischer Punkt in jeder Datenbank ist die Verfügbarkeit von Informationen, und in dieser Hinsicht hat Cassandra eine große Toleranz gegenüber Fehlern, unter denen wir alle leiden müssen, indem alle darin gehosteten Daten zugelassen werden Die Fähigkeit, automatisch auf andere Knoten repliziert zu werden, garantiert deren Integrität und Verfügbarkeit. Darüber hinaus kann ein Knoten, der einen Fehler aufweist, ersetzt werden, ohne dass die Datenbank ausgeschaltet werden muss, was sich auf die Funktionsfähigkeit und Produktivität der Benutzer auswirkt.
- Leistung: Ein Pluspunkt für Cassandra ist die hohe Leistung, mit der es möglich ist, auf ein höheres Niveau der NoSQL-Plattformen zu gelangen, die sowohl im Management als auch in Anwendungen bereits bekannt sind.
- Dezentral: Eine weitere Besonderheit von Cassandra ist die dezentrale Verwaltung, dank derer jeder an der Datenbank beteiligte Knoten eindeutig ist und somit massive Ausfälle vermieden werden.
- Skalierbar: Ein Punkt, den Sie in einer Datenbank berücksichtigen sollten, ist ihre Skalierbarkeit, da sie es ermöglicht, dass die Datenbank mit dem Wachstum des Unternehmens in ihrer Aktion nicht eingeschränkt ist. Deshalb ist Cassandra eine der besten Optionen Laut Statistik kann es bis zu 2000 Knoten, mehr als 400 TB Daten und mehr als 1 Billion Anfragen pro Tag unterstützen, was uns seinen weiten Anwendungsbereich sichert.
- Dauerhaft: Ein weiterer Aspekt, der bei der Auswahl der zu verwendenden Datenbank berücksichtigt werden muss, ist deren Dauerhaftigkeit. Dies bedeutet, dass die Datenbank die Fähigkeit haben muss, dass wichtige Daten unabhängig von der Art des Ausfalls immer verfügbar bleiben Damit ist die optimale und korrekte Verwaltung aller dort gehosteten Daten gewährleistet.
- Steuerungsoptionen: Mit der Cassandra-Datenbank verfügen wir über verschiedene Verwaltungsoptionen, z. B. über synchrone oder asynchrone Replikation. Wenn Sie die asynchrone Verwaltungsoption verwenden, steht eine Datenbank zur Verfügung, die zusätzliche Funktionen wie Hinted Handoff und Read Repair zum Erweitern unterstützt seine Verwendungsmöglichkeiten.
Nun werden wir sehen, wie Cassandra auf CentOS 7 installiert wird.
1. Aktualisieren Sie das System und installieren Sie Java in CentOS 7
Der erste Schritt ist das Aktualisieren des Betriebssystems. Führen Sie dazu den folgenden Befehl aus:
sudo yum update -y
Da Cassandra in Java geschrieben ist, muss Java unter CentOS 7 installiert werden, indem der folgende Befehl ausgeführt wird:
sudo yum installiere java -y
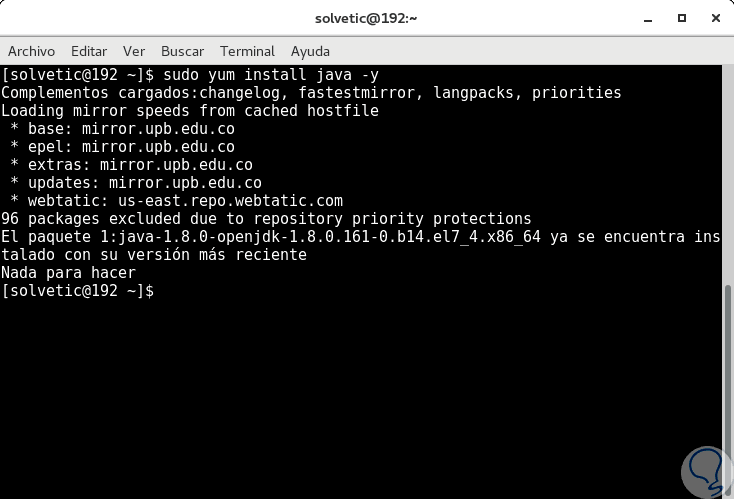
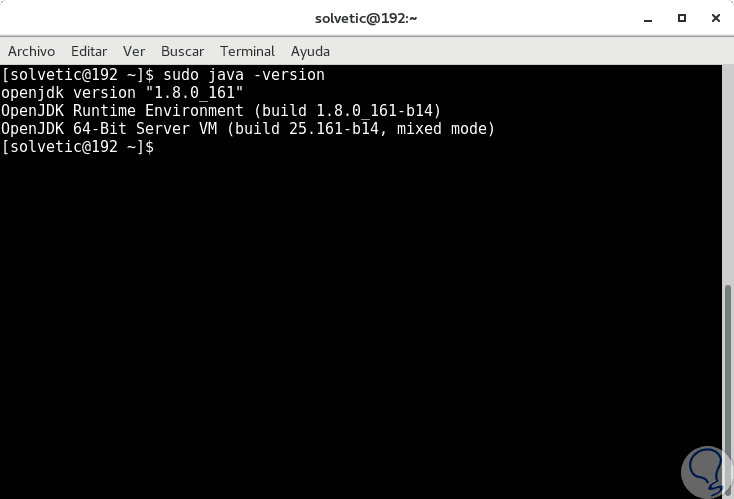
Wir können die installierte Java-Version überprüfen, indem wir den folgenden Befehl ausführen:
Sudo Java-Version
2. Installieren Sie Cassandra in CentOS 7
Standardmäßig ist die Cassandra-Datenbank im Standardrepository von CentOS 7 nicht verfügbar. Aus diesem Grund müssen die offiziellen Apache Software Foundation-Repositorys zu CentOS 7 hinzugefügt werden. Dies wird durch Erstellen der Datei cassandra.repo in der Datei erreicht Verzeichnis /etc/yum.repos.d auf folgende Weise:
sudo nano /etc/yum.repos.d/cassandra.repo
In dieser neu erstellten Datei werden wir Folgendes hinzufügen:
[Kassandra] name = DataStax Repo für Apache Cassandra baseurl = http://rpm.datastax.com/community aktiviert = 1 gpgcheck = 0
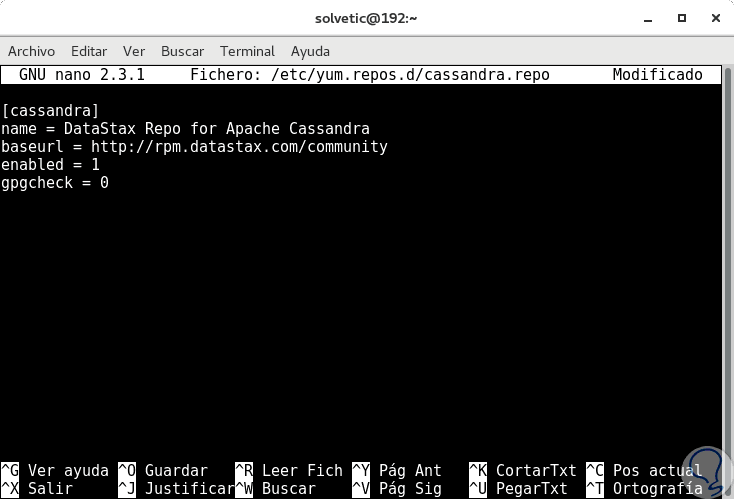
Wir speichern die Änderungen mit der Tastenkombination
+ O Strg + O
und wir verlassen den Editor mit den Tasten
+ X Strg + X
Nun müssen Sie die Repository-Pakete aktualisieren, indem Sie Folgendes ausführen:
sudo yum update -y
Jetzt können wir Cassandra installieren, indem wir den folgenden Befehl ausführen:
sudo yum installiere dsc20 -y
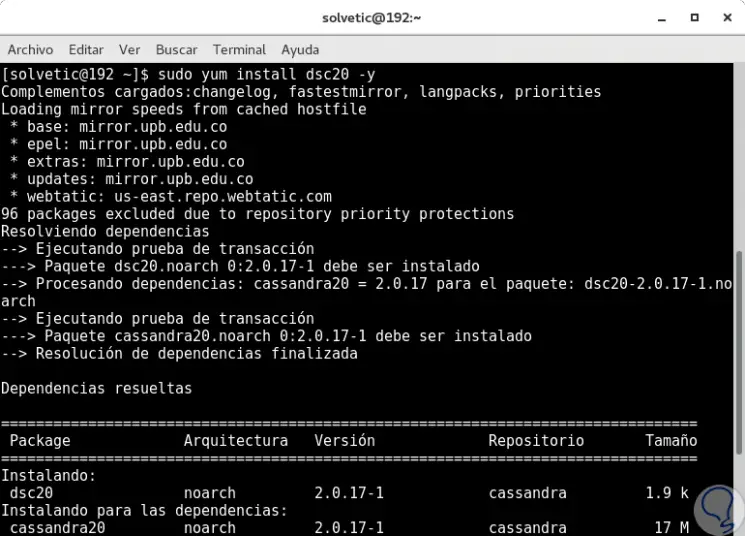
Nach dem Download und der Installation sehen wir Folgendes: 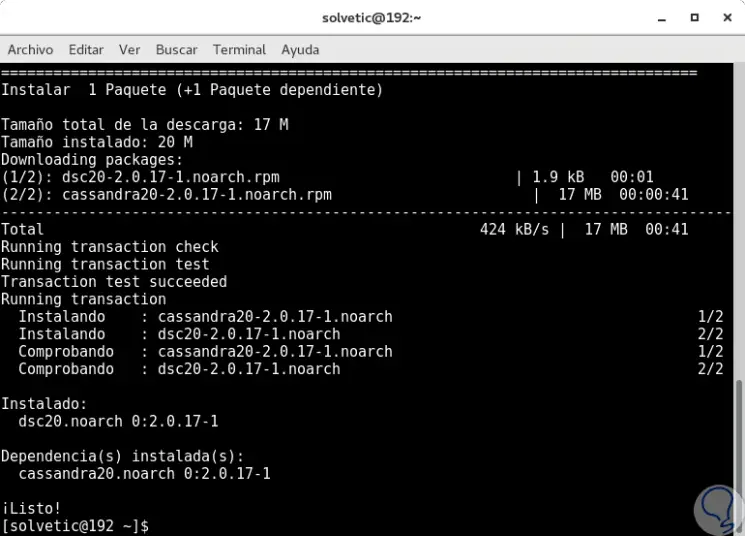
Sobald Cassandra installiert ist, führen wir die folgenden Befehle aus:
sudo systemctl start cassandra (Start des Cassandra-Dienstes) sudo systemctl enable cassandra (Aktivieren des Cassandra-Dienstes beim Systemstart)
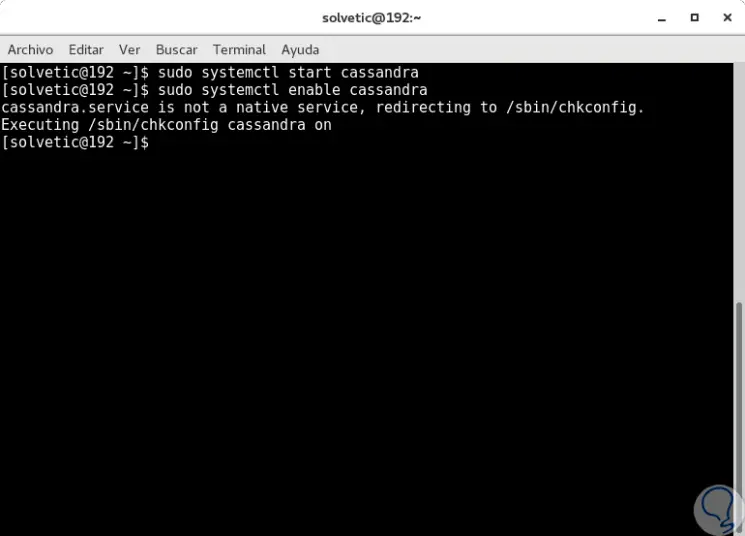
Zum Schluss können wir den Status von Cassandra sehen, indem wir den folgenden Befehl ausführen:
sudo systemctl status cassandra

3. Schließen Sie den Cassandra-Cluster in CenTOS 7 an und überprüfen Sie ihn
An diesem Punkt arbeitet Cassandra, daher werden wir Cassandra Clúster überprüfen und verbinden. Überprüfen wir zunächst den Status des Cassandra-Clusters mit dem folgenden Befehl:
sudo nodetool status
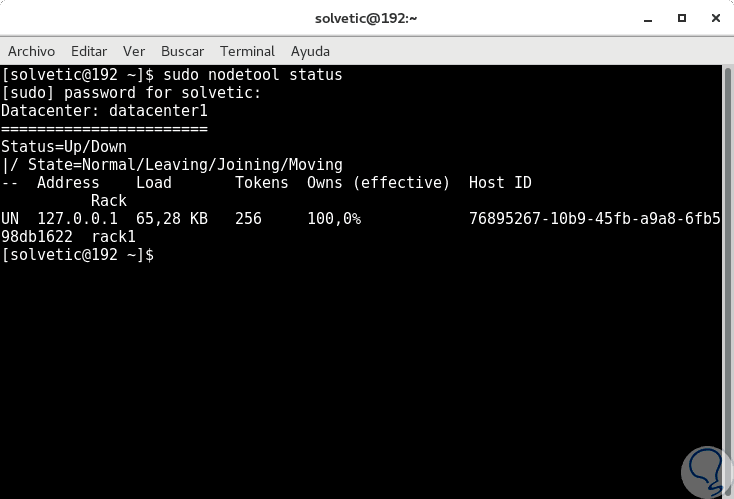
Wir können sehen, dass der Clusterverbindungsstatus korrekt ist. An dieser Stelle möchte TechnoWikis einen Lösungspunkt hinzufügen, da bei der Ausführung dieses Befehls in vielen Fällen der folgende Fehler angezeigt wird:
Fehler: Verbindung zu '127.0.0.1:7199' konnte nicht hergestellt werden: Verbindung abgelehnt (Cassandra)
Um diesen Fehler zu beheben und korrekt darauf zuzugreifen, müssen wir mit dem gewünschten Editor in das folgende Verzeichnis wechseln:
sudo nano /etc/cassandra/default.conf/cassandra-env.sh
Dort müssen wir die folgende Zeile finden:
JVM_OPTS = "$ JVM_OPTS -Djava.rmi.server.hostname =
Das Erscheinungsbild sollte dem folgenden Text ähneln:
Fügen Sie dies hinzu, wenn Sie Probleme beim Herstellen einer Verbindung haben: # JVM_OPTS = "$ JVM_OPTS -Djava.rmi.server.hostname = <öffentlicher Name>"
Dort müssen wir die zweite Zeile auskommentieren und die öffentliche Namenszeile durch die IP-Adresse 127.0.0.1 ersetzen:
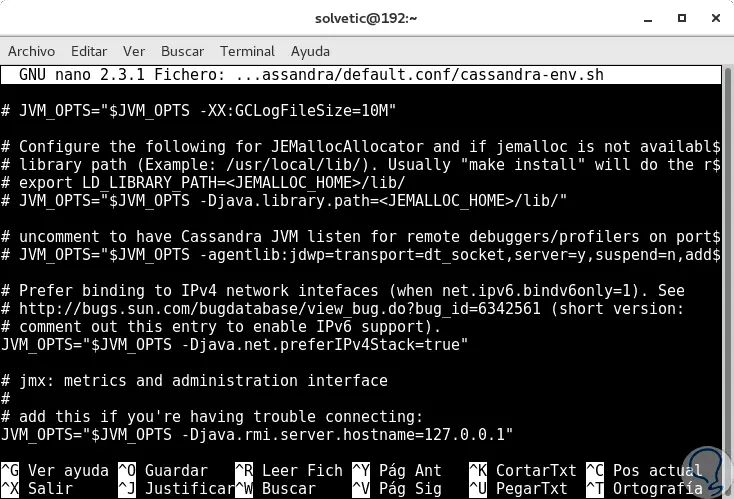
Wir speichern die Änderungen mit der folgenden Tastenkombination:
+ O Strg + O
Wir verlassen den Editor mit:
+ X Strg + X
Wir fahren fort, den Dienst neu zu starten, indem wir Folgendes ausführen:
systemctl Cassandra neu starten
In einigen Fällen wird empfohlen, den Computer neu zu starten. Auf diese Weise wird der Fehler behoben.
Jetzt können wir eine Verbindung zum Cassandra-Cluster herstellen, indem wir den folgenden Befehl ausführen:
cqlsh
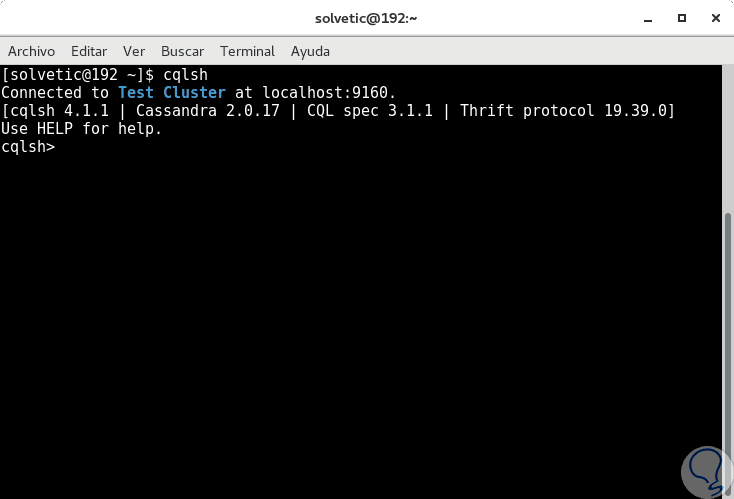
Wir können die entsprechende Verbindung sehen, um mit der Arbeit an dieser Datenbank zu beginnen. Zum Verlassen verwenden wir den Begriff
aussteigen
Auf diese Weise haben wir gesehen, wie man Cassandra in CentOS 7 installiert und darauf zugreift.