Durch Frameworks wie Jquery, Prototype, Mootools und andere, die Anfragen an den Server ermöglichen, erhalten Sie das Ergebnis und aktivieren Sie das Laden bestimmter Inhalte der Seite, ohne das Web zu aktualisieren und völlig transparent für den Benutzer.
Derzeit sind die meisten Webseiten stark von JavaScript abhängig, um Effekte und Funktionen auf der Client-Seite zu erzielen. Dies birgt bekannte Risiken in Bezug auf SEO, Linkprobleme oder Inkompatibilitäten, technische Fehler, Download-Geschwindigkeit usw.

Vor- und Nachteile der Verwendung von AJAX
Die Vorteile in Bezug auf die Benutzererfahrung liegen auf der Hand: Schnelle Seiten, weniger Überlastung für den Server, der nur die Bestellung verarbeitet und den für den Benutzer erforderlichen Inhalt zurückgibt. Viele Webfeatures der neuen Generation lassen sich nicht einfach ohne die Verwendung von JavaScript oder Jquery ausführen, da der Benutzer auf ein Element im Web klicken und der Browser nicht die gesamte Seite, sondern nur einen Inhaltsblock aktualisieren muss und sogar verschiedene Informationen für verschiedene Benutzer anzeigen.
Der Nachteil ist, dass der zurückgegebene Inhalt für die Suchmaschinen möglicherweise nicht sichtbar ist und der Roboter den Jquery- oder Ajax-Code häufig nicht analysiert. Ein Problem ist, dass der Inhalt einer Seite nur für den Browser sichtbar ist, nicht jedoch auf dem Server. Die Art und Weise, wie Roboter verfolgt werden, kann einige Inhalte nicht sehen oder einige Links schlagen fehl, da der Roboter JavaScript nicht verstehen kann das sind sehr komplex.
Google hat die Ajax- und Javascript-Code-Tracking-Funktionen seiner Roboter kontinuierlich weiterentwickelt, während Bing und Yahoo nicht viel weiterentwickelt haben.
Sogar Suchmaschinen können den relevantesten Inhalt für eine Suchabfrage nicht genau darstellen, sodass eine übermäßige Verwendung dieser Technologie zu einer schlechten Positionierung in den Suchergebnissen führen kann.
Beispiele für HTML-Elemente und -Blöcke zur Verbesserung der SEO
Wenn wir einen Block erstellen müssen, wenden wir semantische Namen auf die Klassen an, die den Inhalt sinnvoll beschreiben:
Beispiel für einen Block, der Inhalt anzeigt
<div class = "bloquecentro"> <div class = "blocktop"> </ div> <div class = "containblock"> </ div> </ div>
Es wäre besser, jedem HTML-Codeblock einen semantischeren Sinn zu geben, damit die Roboter verstehen, welchen Inhalt sie zeigen werden:
<div class = "news-section"> <div class = "title-news"> </ div> <div class = "news"> </ div> </ div>
Die Struktur ist eindeutig nachvollziehbar, obwohl der Inhalt nicht im HTML generiert wurde. Da das semantische Markup Schlüsselwörter enthält, ist es wichtig, HTML-Tags zu verwenden, die für den Inhalt geeignet sind, wenn wir im Zweifel das W3school Html-Handbuch konsultieren können.
Wie die geordneten oder ungeordneten Listen dient die Definitionsliste dazu, die inhaltsorientierte Liste anzuzeigen, da im vorliegenden Fall die Nachrichten oder eine Liste von Produkten angezeigt werden können. Dies ermöglicht eine höhere Keyword-Dichte und weniger Unordnung im Code.
Einer der wichtigsten Aspekte ist, dass der von Javascript für den Benutzer erzeugte Inhalt derselbe ist, der auch Suchmaschinen oder Such-Bots angezeigt wird.
Google gibt als mögliche Lösung an, dass wir beschreibenden Text oder Lesezeichen verwenden müssen, wenn unsere Website Technologien enthält, auf die Suchmaschinen nicht zugreifen können oder die sie nicht interpretieren können, z. B. JavaScript oder Ajax, damit diese Elemente angeben können, welche Inhalte übereinstimmen angezeigt werden und somit die Erreichbarkeit der Website verbessern. Viele Benutzer verwenden mobile Geräte, nicht standardmäßige Browser, veraltete Software und langsame Verbindungen. Daher können beim Anzeigen von Inhalten oder bei der Verwendung einiger Funktionen Fehler auftreten.
Die Links und Parameter nach URL
Google bevorzugt, dass der Hashbang als Parameter in einer URL verwendet wird, da es auf diese Weise einfacher ist, seine Links zu interpretieren, wenn wir die Site als Parameter übergeben.
Ein weit verbreitetes Beispiel ist auf der Twitter-Website. Google verwendet es, um den Inhalt dieser statischen Seite beizubehalten und anzufordern. Um zu zeigen, was die umgeschriebenen URLs enthalten, sind hier einige Beispiele:
Diese URL, die durch eine Abfrage generiert wird, ist besser und semantischer als SEO
www.miweb.com/#!madrid/products
Diese beiden URLs sind für Roboter schwieriger zu verstehen, aber die letzte verbessert definitiv die Semantik.
www, miweb, com /? tmp = madrid / products
www.miweb.com/?ciudad=madrid&seccion=productos
y mostrar el mismo contenido que un usuario vería en los buscadores, esto no representa un gran problema. Zwar können wir semantisches SEO für den generierten Inhalt durchführen und denselben Inhalt anzeigen, den ein Benutzer in den Suchmaschinen sehen würde, dies ist jedoch kein großes Problem.
Schieberegler und Navigationsleisten
Wenn der Inhalt auf Registerkarten verteilt wird und sich der Inhalt durch eine Abfrage oder ein anderes Framework entsprechend der von uns positionierten Registerkarte ändert, muss für jede Registerkarte eine separate URL angegeben werden. Wenn der Benutzer auf eine Registerkarte klickt, kann auch eine Anforderung gestellt werden an den Server, um völlig neue Inhalte zu generieren. Die Struktur jedes Links könnte etwa so aussehen:
www.miweb.com?tab=sales
www.miwebe.com/?tab=clientes
www.miweb.com/?tab=products
Der Trick mit den Registerkarten wird mit CSS und Javascript erzeugt, der Server gibt den Inhalt aller Registerkarten mit der ersten Seitenanforderung zurück. Wenn der Benutzer auf eine Registerkarte klickt, führt die in CSS definierte Klasse dazu, dass der Browser den mit einer Registerkarte verknüpften Inhalt verbirgt und nur den Inhalt anzeigt, der sich auf die angeklickte Registerkarte bezieht, während die anderen ausgeblendet sind, sich jedoch im Code befinden. erlaubt ist, so ist es gut, der Struktur eine semantische Bedeutung zu geben.
Es ist auch sehr wichtig, dass keine Javascript- oder CSS-Dateien auf unserer Website gecrawlt werden, da dies die Positionierung und Indizierung Ihrer Inhalte beeinträchtigen und zu Fehlern bei der Verfolgung von Statistiken führen kann.
Eine der Richtlinien des Google-Webmasters besagt ausdrücklich, dass diese Dateien nicht nachverfolgt, aber weder blockiert noch für die Roboter ausgeblendet werden sollen.
Google Webmaster-Tools zum Überprüfen und Analysieren des Crawls
Mit den Google Webmaster-Tools können wir Google über die Inhaberschaft unserer Website informieren. Melden Sie sich mit Ihrem Google- oder Google Mail-Konto an und wir können unsere Website überprüfen.
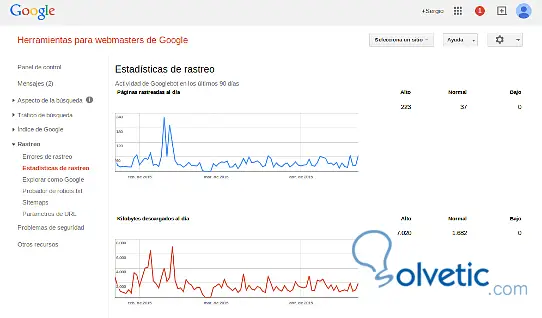
Nachdem Sie die Eigenschaft überprüft haben, können Sie die Datei sitemap.xml senden , um die Website zu verfolgen. Anschließend beginnt Google mit der Indizierung Ihrer URLs.
Der Roboter benötigt ungefähr zwei Wochen, bis die Links in der Google-Suche korrekt angezeigt werden.
Es gibt keine einfache Möglichkeit, um sicherzustellen, dass alles funktioniert, aber es gibt einige Tools, mit denen Sie sehen können, was passiert. Verwenden Sie am besten das Explorer-Tool wie Googlebot, das genau anzeigt, was Google beim Crawlen der Website sieht. Sie können unter Diagnose auf die Google Webmaster-Tools zugreifen.