In diesem zweiten Teil werden wir alles ausführen, was mit Python geplant wurde. Aufgrund der Komplexität der verschiedenen Aspekte des Projekts ist es möglich, dass wir bei unserer ersten Implementierung nicht alles perfekt haben. Dies ist jedoch gut, da es uns die Möglichkeit gibt mit einem Prototyp, der arbeitet, um seine Komponenten zu verbessern.
Inhalte verwalten
Unsere erste Aktion besteht darin, den Inhalt unserer XML-Datei zu verwalten. Dazu verwenden wir SAX , das wir bereits installiert oder überprüft haben, wie wir es im vorherigen Teil des Tutorials getan haben.
Dazu erstellen wir zunächst einen Container, an den wir unsere erstellte XML-Datei übergeben.
Sehen wir uns den Code an, den wir platzieren müssen:
aus xml.sax.handler importieren Sie ContentHandler aus xml.sax importieren analysieren Klasse TestHandler (ContentHandler): bestanden parse ('website.xml', TestHandler ())
Wenn wir dies ausführen, sollten wir keinen Fehler haben, das bedeutet, dass unser XML bereits geladen ist und dass der Parser seine Arbeit erledigt hat. Falls wir einen Fehler oder eine Ausnahme sehen, die wir dokumentieren müssen, um zu sehen, was die Ursache ist, können wir uns im Internet und im Umfang unterstützen Dokumentation, die Python hat.
Jetzt werden wir eine Methode hinzufügen, die uns zeigt, dass das, was wir abgeleitet haben, wahr ist. In unserer TestHandler- Klasse werden wir den folgenden Code integrieren:
def startElement (self, name, attrs): Druckname, attrs.keys ()
Wenn Sie unser Programm erneut ausführen, sehen Sie etwas wie das folgende Bild:
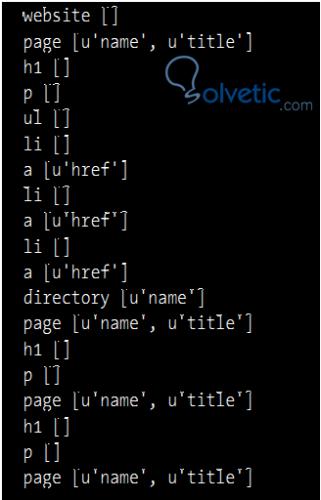
Der nächste Schritt besteht nun darin, die Informationen zu erhalten, die jedes Element enthält. Dazu werden die Methoden der SAX ContentHandler- Klasse einbezogen und die in unserer XML-Datei vorhandenen H1-Elemente abgerufen .
Unsere Klasse sollte wie folgt sein:
aus xml.sax.handler importieren Sie ContentHandler aus xml.sax importieren analysieren Klasse HeadlineHandler (ContentHandler): in_headline = False def __init __ (self, headlines): ContentHandler .__ init __ (selbst) self.headlines = Überschriften self.data = [] def startElement (self, name, attrs): wenn name == 'h1': self.in_headline = Wahr def endElement (self, name): wenn name == 'h1': text = '' .join (self.data) self.data = [] self.headlines.append (text) self.in_headline = False def Zeichen (self, string): if self.in_headline: self.data.append (string) Überschriften = [] parse ('website.xml', HeadlineHandler (Überschriften)) print 'Folgende <h1> Elemente wurden gefunden:' für h in Überschriften: print h
Wie wir am Ende sehen, zählen wir die Übereinstimmungen mit den H1-Elementen und machen einen Eindruck von der Menge und dem, was sie enthalten. In unserer Konsole sehen wir Folgendes:
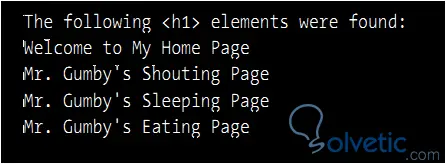
Erstellen Sie unsere erste Seite
Da wir alle erforderlichen Tests durchgeführt haben und wissen, wie unser SAX-Parser funktioniert, ist es Zeit, unsere erste Seite aus unserem Archiv zu erstellen.
Zu diesem Zweck erstellen wir eine Methode, mit der eine HTML-Erweiterungsdatei erstellt wird. Wir platzieren den entsprechenden HTML-Header , suchen die verschiedenen Elemente in der XML-Datei, platzieren sie in unserer neuen Datei und schließen schließlich die Datei, in der sie platziert wird Die rechte Fußzeile ist ein gültiges HTML-Dokument.
Schauen wir uns den Code an, der das alles macht:
aus xml.sax.handler importieren Sie ContentHandler aus xml.sax importieren analysieren Klasse PageMaker (ContentHandler): Passthrough = False def startElement (self, name, attrs): if name == 'page': self.passthrough = True self.out = open (attrs ['name'] + '.html', 'w') self.out.write ('<html> <head> n') self.out.write ('<title>% s </ title> n'% attrs ['title']) self.out.write ('</ head> <body> n') elif self.passthrough: self.out.write ('<' + name) für Schlüssel, Wert in attrs.items (): self.out.write ('% s = "% s"'% (Schlüssel, Wert)) self.out.write ('>') def endElement (self, name): if name == 'page': self.passthrough = False self.out.write (' n </ body> </ html> n') self.out.close () elif self.passthrough: self.out.write ('</% s>'% name) def Zeichen (self, chars): if self.passthrough: self.out.write (Zeichen) parse ('website.xml', PageMaker ())
Wenn wir unseren Code in dem Verzeichnis ausführen, in dem sich die Quellcodedatei befindet, erhalten wir eine HTML-Datei, die etwa Folgendes enthält:
<html> <head> <title> Homepage </ title> </ head> <body> <h1> Willkommen auf meiner Startseite </ h1> <p> Hi, da. Mein Name ist Mr. Gumby und dies ist meine Homepage. Hier Ich habe folgende Interessen: </ p> <ul> <li> <a href="interests/shouting.html"> Schreien </a> </ li> <li> <a href="interests/sleeping.html"> Schlafen </a> </ li> <li> <a href="interests/eating.html"> Essen </a> </ li> </ ul> </ body> </ html>
Wenn wir es in einem Browser ausführen, werden wir sehen, dass es richtig interpretiert wird und wir werden ein Ergebnis ähnlich dem folgenden haben:
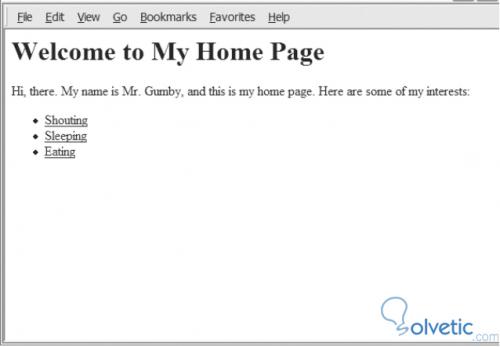
Um dies zu erreichen, schließen wir unsere erste Iteration und dieses Tutorial ab. Es liegt an jedem von uns, das Projekt zu erweitern, um alle erworbenen Kenntnisse zu verbessern und das erste Programm noch weiter zu verbessern.