Mit Python können wir mit Remotedateien arbeiten. Dies klingt möglicherweise nicht logisch. In diesem Fall sind die Remotedateien jedoch nicht mehr als Webseiten aus unserem Python-Programm. Der Grund dafür kann in der Erstellung von Webabfragen liegen REST-Services , mit denen wir Werte von GET erhalten oder Seiten direkt aufrufen und deren Inhalt manipulieren können.
Um dies zu erreichen, werden wir einige der vielen Bibliotheken verwenden, die Python für die Arbeit mit Netzwerken anbietet. Dadurch werden die technischen Hindernisse beseitigt und wir konzentrieren uns nur darauf, wie wichtig es für unsere Programmierlogik ist.
Diese beiden Bibliotheken urllib und urllib2 ermöglichen es uns, über das Netzwerk auf Dateien zuzugreifen, als befänden sie sich in unserer lokalen Umgebung. Durch einen einfachen Aufruf einer Funktion kann dies für viele Dinge nützlich sein, die wir beispielsweise verwenden können ein Web und mit seinem Inhalt, um in unserem Programm zu berichten, was wir darin finden können.
Diese beiden Bibliotheken sind ähnlich. Der Unterschied besteht darin, dass urllib2 möglicherweise etwas komplexer ist. Wenn wir einfach eine Abfrage ohne weitere Implikationen durchführen möchten , können wir urllib verwenden . Wenn wir jedoch einen Authentifizierungsprozess ausführen oder Cookies verwenden möchten , ist urllib2 möglicherweise eine Lösung Seien Sie die richtige Wahl für unser Programm.
Da wir theoretisch wissen, was wir brauchen und warum wir es brauchen, sehen wir uns ein kleines Beispiel im Code an, um zu verdeutlichen, dass wir dies tun können. Im folgenden Beispiel öffnen wir ein Web aus unserem Programm und extrahieren dann durch reguläre Ausdrücke a Link seines Inhalts dafür verwenden wir urllib :
>>> aus urllib import urlopen >>> webpage = urlopen ('http://www.python.org') >>> wieder importieren >>> text = webpage.read () >>> m = re.search ('<a href="([^"[+)"> Tutorial </a>', Text, re.IGNORECASE) >>> m.group (1)
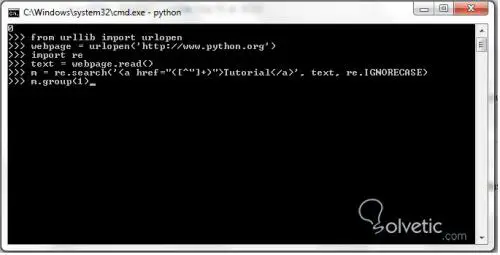
Wir gehen Schritt für Schritt vor und erstellen zunächst die urllib-Bibliothek, die wir mit urlopen importieren. Anschließend erstellen wir eine Variable namens webpage , die das Ergebnis von urlopen enthält , das wir mit der offiziellen Seite von Python ausführen Normalerweise sagen wir, dass Text die Variable ist, die den Inhalt des Lesens der Seite enthält. Wir führen eine Suche mit regulären Ausdrücken durch und gruppieren schließlich das Ergebnis, das wir ausgeben sollen:
http://docs.python.org/
Dank der urlopen- Methode können wir die Webseite so bearbeiten, als wäre sie ein Dateiobjekt. Auf diese Weise können wir viele der Funktionen anwenden, die wir für diese Art von Objekten verwenden können, auch wenn wir sie herunterladen möchten Sie können die Seite auf einfache Weise von unserem Standort aus mit der urlretrieve- Methode wie folgt bearbeiten :
urlretrieve ('http://www.python.org', 'C: \ python_webpage.html')
Das Einzige, was wir tun, ist, als zweiten Parameter die Route in unserer lokalen Umgebung zu übergeben, auf der die Datei mit der Kopie der Seite ohne große Schwierigkeiten gespeichert werden soll.
Damit beenden wir dieses Tutorial, da es dank der Python- Bibliotheken recht einfach ist, komplexere Arbeiten durchzuführen, da Seiten in unseren Programmen verwendet werden.