Angesichts der gegebenen Situation ist das Ideal, ein Programm zu generieren, mit dem wir diese Einschränkungen lösen können. Dafür haben wir Python und dank der verschiedenen Tools für die Textverarbeitung können wir die Lösung erstellen, mit der wir diese Aufgabe erledigen können.
Bedingungen
Um ein Problem zu lösen, müssen wir zuerst bestimmte Bedingungen festlegen, unter denen wir wissen, was zu tun ist. Für dieses spezielle Projekt werden wir Folgendes festlegen:
- Der Text sollte keine Art von Code oder Beschriftungen enthalten .
- Muss in der Lage sein, Titel, Absätze und Listen sowie hervorgehobenen Text und URLs zu unterscheiden .
- Es muss robust genug sein, um auf andere Auszeichnungssprachen als HTML angewendet werden zu können.
Wie wir sehen können, sind dies breite, aber nicht unmögliche Bedingungen. In der ersten Implementierung ist es jedoch möglicherweise nicht möglich, alle zu erreichen, da wir hierfür mehrere Prototypen ausführen müssen.
Zu verwendende Werkzeuge
Um die gesetzten Ziele zu erreichen, müssen wir definieren, welche Werkzeuge wir verwenden sollen. In diesem Fall können wir die Standardeingabebibliothek sys.stdin verwenden und für die Ausgabe müssen wir genug drucken . Alles andere ist, mit verschiedenen Techniken zu arbeiten, die wir in den Beispielen sehen werden.
Zuhause
Da wir wissen, was wir brauchen und unsere Ziele festgelegt haben, sollten wir nur eine Möglichkeit haben, unseren Erfolg zu messen. Dazu ist es erforderlich, dass wir ein Dokument erstellen, mit dem wir unsere Seiten generieren können. Im Fall dieses Tutorials sehen wir ein Beispieldokument im Im nächsten Bild wird jedoch ein beliebiger Text angezeigt, sofern er mehrere Absätze enthält:
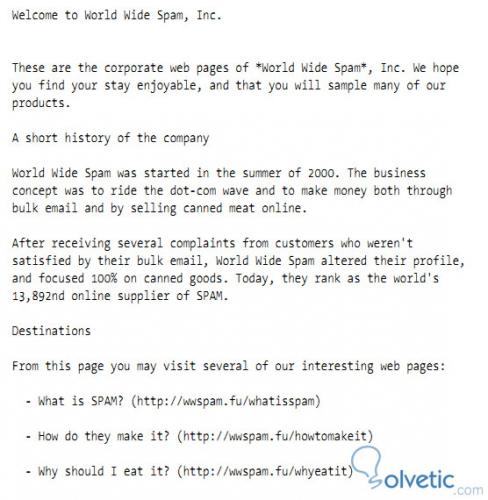
Erste Iteration
In der ersten Iteration müssen wir die Absätze teilen. In diesem Fall werden wir sie Blöcke nennen. Wir wissen, dass diese Blöcke durch eine oder mehrere Leerzeilen getrennt sind. Dann besteht unser erster Schritt darin, diese Zeilen als Trennzeichen zu verwenden.
Der nächste Code, den Sie ausführen, besteht darin, die gefundenen Zeilen zu sammeln, bis Sie eine leere Zeile finden. Scrollen Sie dann weiter durch die Datei, bis Sie eine andere Textgruppe finden.
Mal sehen, wie der Code aussieht:
def lines (Datei): für Zeile in Datei: Ertragszeile Ausbeute ' n' def blocks (Datei): block = [] für Zeile in Zeile (Datei): if line.strip (): block.append (Zeile) Elif-Block: ergeben '' .join (block) .strip () block = []
Der vorherige Code wird in einer Datei mit dem Namen util.py gespeichert. Anschließend müssen die verschiedenen Tags in das resultierende HTML-Dokument eingefügt werden. Dazu wird eine weitere Datei mit dem folgenden Code generiert:
von __zukünftigen__ Importgeneratoren Import sys, re von util import * print '<html> <head> <title> ... </ title> <body>' title = 1 für Block in Blöcken (sys.stdin): block = re (r ' * (. +?) *', r '<em> 1 </ em>', block) wenn Titel: print '<h1>' Druckblock print '</ h1>' title = 0 sonst: print '<p>' Druckblock print '</ p>' print '</ body> </ html>'
Wie wir sehen, verwenden wir die blocks () -Methode und übergeben die Eingabedatei dank der sys.stdin- Bibliothek. Die Datei muss simple_markup.py heißen und wird folgendermaßen ausgeführt:
$ python simple_markup.py <test_input.txt> test_output.html
Wie wir sehen, übergeben wir die ursprüngliche Textdatei und den Namen, den die Ausgabe enthalten soll und der so aussehen soll:
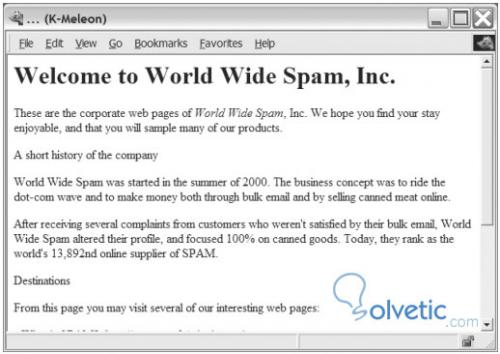
Nach Abschluss der ersten Iteration beenden wir dieses Tutorial. Im zweiten Teil werden wir diese Konzepte sowie die zweite Iteration für dieses Programm weiter vertiefen.