In früheren Tutorials haben wir uns vollständig mit
CQL und der Art und Weise befasst, in der es uns hilft,
Cassandra zu verwalten. Wir haben die grundlegenden Operationen für die
Schlüsselbereiche und die Tabellen in Cassandra gesehen und konnten sie für die Erstellung einer anfänglichen Struktur in der Datenbank anwenden. Es gibt jedoch eine Menge fortgeschrittener Konzepte, die wir kennen müssen, um Cassandra optimal nutzen zu können.
Diese Konzepte oder Eigenschaften, um sie auf irgendeine Weise zu nennen, ermöglichen es uns, verschiedene Funktionalitäten in unseren Tabellen zu erreichen, was uns einen viel breiteren Bereich an Möglichkeiten bietet als die übrigen NoSQL-Datenbanken .
Datentypen
Früher haben wir einige Tabellen erstellt und Werte als Text oder Datum für unsere Spalten verwendet. Dies ist jedoch nicht alles, was CQL zur Verfügung hat. Sehen wir uns die Datentypen an, die wir für unsere Operationen haben:
ascii
Zeichenkette vom Typ US-ASCII.
bigint
Ganzzahliger Wert mit einer Länge von 64 Bit.
Klecks
Der Datentyp, der in der CQL- Befehlskonsole als Hexadezimalzahl ausgedrückt wird, besitzt außerdem keine Validierung und basiert auf beliebigen Bytes.
Boolescher Wert
Der klassische Typ von Booleschen Daten, bei dem die Werte wahr oder falsch sein können.
Zähler
counter ist ein neuer Datentyp für diejenigen von uns, die aus der relationalen Welt stammen und angeben, dass er 64 Bit verteilt ist.
dezimal
Eine andere Art von Daten, die wir erkennen können, die uns eine dezimale Genauigkeit für unsere Informationen gibt.
verdoppeln
Datentyp Gleitkomma aber basierend auf 64 Bit.
schweben
Wie das vorherige ist es ein Gleitkomma-Datentyp, der jedoch auf 32 Bit basiert.
inet
Dieser Typ ist sehr speziell und gleichzeitig sehr nützlich und ermöglicht es uns, eine Zeichenfolge einer IP-Adresse zu speichern. Er unterstützt sowohl das IPV4- als auch das IPV6- Format .
int
Der klassische Typ von vollständigen Daten, der Zahlen von bis zu 32 Bit unterstützt.
Liste
Eine andere Art von Daten, die in Cassandra debütiert und es uns ermöglicht, eine geordnete Sammlung von Elementen zu speichern.
Karte
“Like List” ist eine andere Art neuer Daten und ermöglicht das Speichern eines assoziativen Arrays, das für die Entwicklung von Anwendungen sehr nützlich ist.
setzen
Ähnlich wie in der Datentypliste wird eine Sammlung von Elementen gespeichert, jedoch ohne eine bestimmte Reihenfolge.
text
Speichert eine codierte Zeichenfolge.
Zeitstempel
Datentyp, der Datum und Uhrzeit speichert und als 8-Byte-Ganzzahl codiert ist.
varint
Art der Genauigkeitsdaten für beliebige Ganzzahlen.
Wie wir sehen, gibt es viele Arten von Daten, die wir erkennen können, wenn wir aus der relationalen Welt stammen, wie andere, die wir zum ersten Mal sehen werden und die Cassandra von anderen Datenbanken abheben.
Eigenschaften von Tabellen
In Cassandra gibt es nicht nur Datentypen für unsere Tabellen. Dank CQL können wir die Tabellen in unseren Datenbankeigenschaften zuweisen, was uns bei Wartungs- und Entwicklungsaufgaben enorm hilft. Lassen Sie uns sehen, was wir zur Verfügung haben.
Caching
Diese Eigenschaft optimiert den Cache-Speicher. Die für diese Eigenschaft verfügbaren Ebenen sind alle oder alle, nur keys_only oder nur keys, nur rows_only oder nur rows und keine oder keine. Alle Optionen sind sehr nützlich, row_only sollte jedoch mit Vorsicht verwendet werden, da Cassandra bei Verwendung dieser Option eine beträchtliche Datenmenge im Speicher ablegt .
Kommentar
Eine Option, die im relationalen Modell vorhanden ist und von Administratoren oder Entwicklern verwendet wird, um Notizen zu machen und wichtige Details in den Tabellen hervorzuheben.
Verdichtung
Mit dieser Eigenschaft kann die Strategie für die Verwaltung der Menüs definiert werden. Es kann sich um folgende Arten handeln: Die erste SizeTiered-Methode, die ausgelöst wird, wenn die Tabelle ein Limit überschreitet. Der Vorteil dieser Strategie besteht darin, dass die Schreibleistung dadurch nicht beeinträchtigt wird Ein Nachteil ist, dass gelegentlich die doppelte Größe der Daten auf der Festplatte verwendet wird, was zu einer schlechten Leseleistung führt. Die zweite Strategie ist LeveledCompaction. Sie arbeitet im Laufe der Zeit auf verschiedenen Ebenen und verbindet die Tabellen mit längeren, was zu einer ziemlich guten Leseleistung führt.
Kompression
Diese Eigenschaft bestimmt, wie die Informationen komprimiert werden. Wir können auswählen, ob Dienste in Bezug auf Geschwindigkeit oder Speicherplatz abgerufen werden sollen, wobei bei höherer Geschwindigkeit weniger Speicherplatz auf der Festplatte gespart wird.
Gc_grace_seconds
Diese Eigenschaft definiert die Wartezeit zum Entfernen von Informationen von den Tombstones. Standardmäßig sind es 10 Tage.
Populate_io_cache_on_flush
Diese Eigenschaft ist standardmäßig deaktiviert, und wir müssen sie nur aktivieren, wenn wir hoffen, dass alle Informationen in den Cache-Speicher passen.
Read_repair_chance
Eine recht interessante Eigenschaft, die eine Zahl zwischen 0 und 1,0 angibt, die die Wahrscheinlichkeit angibt, dass die Informationen repariert werden, wenn das Quorum nicht erreicht wird. Der Standardwert ist 0.1.
Replicate_on_write
Diese Eigenschaft gilt nur für Zählertabellen. Wenn dies definiert ist, werden die Replikate in alle betroffenen Replikate geschrieben, wobei die angegebene Konsistenzstufe ignoriert wird.
Wir wissen dann, dass es sowohl auf der Ebene der Datentypen als auch der Eigenschaften an der Zeit ist, einige der Dinge, die wir gelernt haben, auf unsere Tabellen in Cassandra anzuwenden.
Zuerst erstellen wir eine einfache Tabelle, auf die wir die Eigenschaft von Kommentaren anwenden. Sehen wir uns die Syntax an, die wir dafür verwenden werden:
TABELLE ERSTELLEN Artikel (Titeltext, Inhaltstext, Kategorietext, PRIMARY KEY (Titel)) WITH comment = 'Tabelle zum Speichern der Artikelinformationen';
Wir öffnen unsere CQL- Befehlskonsole und erstellen unsere Tabelle mit der genannten Eigenschaft. Schauen wir uns an, wie sie aussieht:
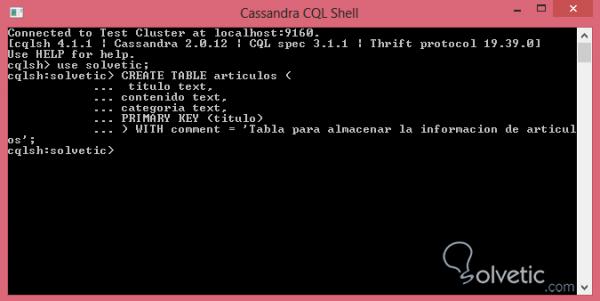
Wie wir wissen, gibt die Befehlskonsole nichts zurück, außer dass kein Fehler vorliegt. Wenn wir diese Änderungen jedoch sehen möchten, können wir in unserem OpsCenter überprüfen, ob alles korrekt abgelaufen ist:
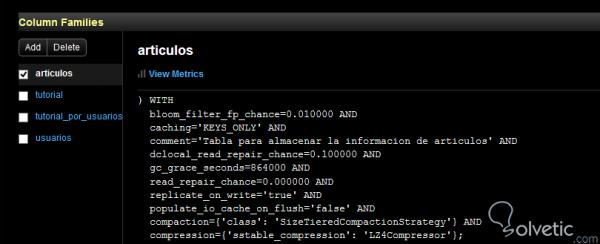
Wie wir sehen, können wir unseren Kommentar und andere Eigenschaften mit ihren Standardwerten sehen. Es ist wichtig zu erwähnen, dass die Definition der restlichen Eigenschaften in Cassandra recht einfach ist, wie wir im vorherigen Beispiel gesehen haben. Mit der WITH- Syntax können wir dies problemlos tun.
Kompression und Verdichtung
Wir werden ein weiteres Beispiel machen, in dem wir die Komprimierungs- und Komprimierungseigenschaften definieren werden, aber dafür ist es wichtig zu wissen, dass diese eine Reihe von Unteroptionen für ihre Verwendung haben.
Sstable_compression
Diese Option gibt den zu verwendenden Komprimierungsalgorithmus an. Die Werte lauten: LY4Compressor, SnappyCompressor und DeflateCompressor .
Chunck_length_kb
Die Tabellen werden blockweise komprimiert. Längere Werte sorgen normalerweise für eine bessere Komprimierung, erhöhen jedoch die Größe der zu lesenden Informationen. Standardmäßig ist diese Option auf 64 KB eingestellt.
Das Manipulieren der Komprimierungsoptionen kann zu einer signifikanten Leistungssteigerung führen, einschließlich vieler Implementierungen von Cassandra, bei denen diese Werte standardmäßig verwendet werden, aber für deren Perfektion ist es erforderlich, diese Werte zu verwenden. Lassen Sie uns jetzt sehen, dass wir für die Verdichtung wissen sollten :
Aktiviert
Legt fest, ob die Eigenschaft in der Tabelle ausgeführt wird, obwohl standardmäßig für alle Eigenschaften die Komprimierung aktiviert ist.
Klasse
Hier definieren wir die Art der Strategie für die Verwaltung der Tabellen.
min_threshold
Dieser Wert ist in der SizeTiered- Strategie verfügbar und gibt die Mindestanzahl von Tabellen an, die zum Starten eines Komprimierungsprozesses erforderlich sind. Es ist standardmäßig in 4 definiert.
max_threshold
Verfügbar auf die gleiche Weise in der SizeTiered- Strategie und definiert die maximale Anzahl der in der Komprimierung verarbeiteten Tabellen. Es ist standardmäßig in 32 definiert.
Dies sind einige der wichtigsten Optionen für diese Eigenschaften. Wichtig zu erwähnen ist, dass für die Definition dieser Optionen eine JSON- Syntax verwendet werden muss, um gültig zu sein. Sehen wir uns ein Beispiel für die Aufnahme dieser beiden Eigenschaften an:
CREATE TABLE table_for_properties (int-ID, Textname, Texteigenschaft, Varint-Nummer, PRIMARY KEY (id)) WITHcompression = {'sstable_compression': 'DeflateCompressor', 'chunk_length_kb': 64} ANDcompaction = {'class': 'SizeTieredCompactionStrategy', 'min_threshold': 6};
Wie wir sehen, haben wir die Art der Komprimierung geändert und die Größe dafür definiert. Zusätzlich haben wir für die Komprimierung die übliche Strategie mit dem Klassenwert verlassen und den min_threshold als 6 definiert, um den Standardwert zu erhöhen Wir führen es in unserer Kommandokonsole aus:
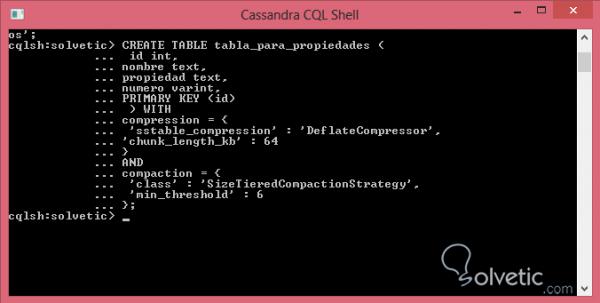
Sortieren der Daten im Cluster
Im letzten Tutorial haben wir gesehen, dass als Ergebnis der Definition von mehr als einem Primärschlüssel diese als Clustering-Schlüssel erstellt werden und die Art und Weise angeben, in der Cassandra die Informationen anordnet. Standardmäßig wird die Reihenfolge aufsteigend definiert und eine Abfrage in absteigender Reihenfolge durchgeführt könnte zu Performance-Problemen führen, aber Cassandra hat eine Lösung für jedes Problem und es ist mit dem Satz CLUSTERING ***** BY . Mal sehen, wie man es benutzt.
CREATE TABLE users_ordered (Benutzertext, Zeitstempel des Datums, Gehaltsvorstellung, Abteilungstext, Supervisortext, PRIMARY KEY (Benutzer, Datum)) WITH CLUSTERING ***** BY (Datum DESC);
Lassen Sie uns unsere Syntax in der Befehlskonsole ausführen und sehen, wie sie aussieht:
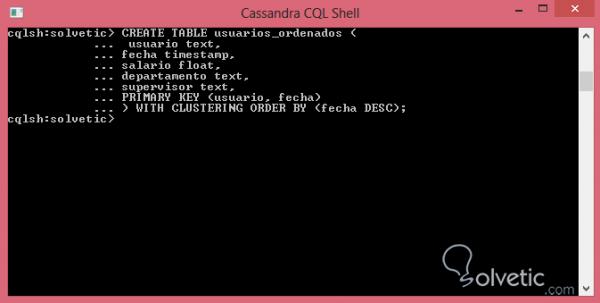
Wie wir sehen konnten, war es ziemlich einfach, dieses Problem mit einer einfachen Zeile zu lösen, aber das Wichtigste ist, dass wir unser Wissen über die Verwaltung der Tabellen in Cassandra erweitern konnten Wir müssen für eine optimale Erstellung von Tabellen in Cassandra wissen.