Die Betriebssysteme basieren auf Befehlszeilen, die uns mehrere Optionen bieten , um die Funktionen der Distribution zu erweitern und Suchvorgänge, Verwaltungsaktionen, Support und vieles mehr auszuführen.
Nur eine dieser Optionen hängt mit der Möglichkeit zusammen, in Linux nach bestimmten Dateitypen zu suchen und auf diese Weise leicht auf deren Inhalt zuzugreifen. Aus diesem Grund werden wir heute über pdfgrep sprechen, das sich auf die Suche nach PDF- Dateien konzentriert .
Einige seiner Eigenschaften sind:
- Kompatibel mit Grep können wir viele grep-Parameter wie -r, -i, -no -c ausführen.
- Möglichkeit, in mehreren PDF-Dateien nach Text zu suchen
- Diese GNU Grep-Farboption ist für bestimmte Farben geeignet und standardmäßig aktiviert.
- Unterstützt die Verwendung von regulären Ausdrücken.
- Freie Software
Um auf dem Laufenden zu bleiben, sollten Sie unseren YouTube-Kanal abonnieren. ABONNIEREN
1. Installieren Sie Pdfgrep unter Linux
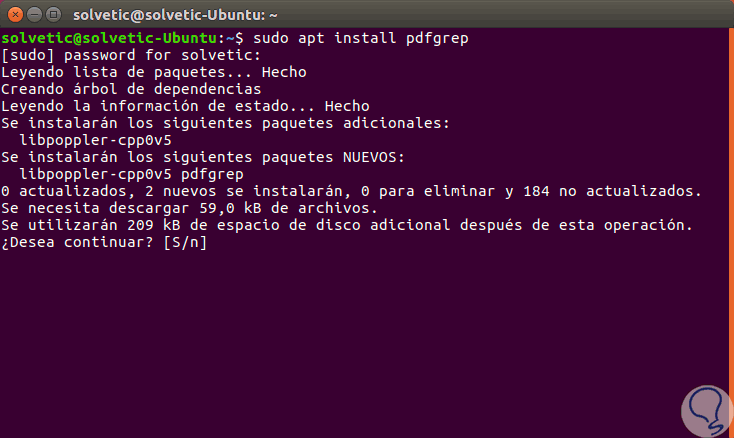
In diesem Fall verwenden wir Ubuntu, es reicht also aus, die folgende Zeile auszuführen. Dort geben wir den Buchstaben S ein, um den Download und die Installation der Pakete zu akzeptieren.
sudo apt install pdfgrep
Andere Installationsoptionen sind:
- Laden Sie die .TAR.GZ-Datei unter folgendem Link herunter.
- Oder führen Sie den folgenden Befehl aus:
Git-Klon https://gitlab.com/pdfgrep/pdfgrep.git
Dann geben Sie jede der folgenden Zeilen in Ihrer Bestellung ein:
./configure machen sudo make install
2. Verwenden Sie Pdfgrep unter Linux
Nach der Installation von pdfgrep ist dies die zu verwendende Syntax:
pdfgrep [OPTION ...] MUSTER [ARCHIV]
Jedes der Elemente sind:
- Option: Gibt die Attribute an, die bei der Suche hinzugefügt werden können, z. B. -i oder –ignore-case , wobei die Unterscheidung von Groß- und Kleinbuchstaben zwischen dem angegebenen Muster und dem Muster, das mit der Datei übereinstimmen muss , ignoriert wird.
- Muster: Zeigt einen erweiterten regulären Ausdruck an.
- Datei: Dies ist die PDF-Datei, in der die Suche ausgeführt wird.
Wir beginnen mit einer einfachen Suche, suchen beispielsweise in der Datei TechnoWikis.pdf nach dem Wort TechnoWikis und führen dazu Folgendes aus:
pdfgrep TechnoWikis TechnoWikis.pdf
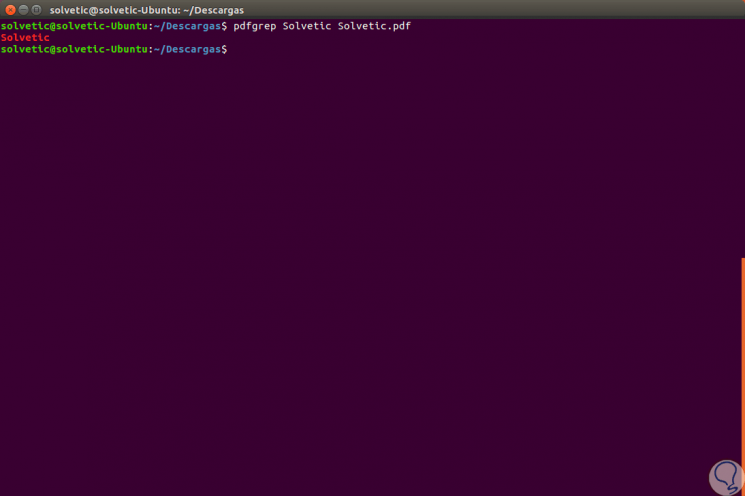
In diesem Fall ist diese Datei nur einmal vorhanden. Jetzt suchen wir in einer offiziellen Microsoft PDF-Datei nach dem Begriff Windows. Das Ergebnis ist: 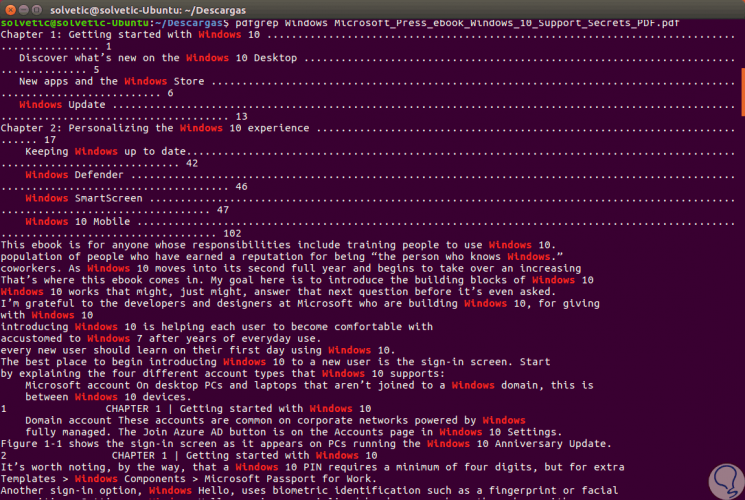
Wir können sehen, dass das gesuchte Wort hervorgehoben ist, was die Lokalisierung erleichtert. Wenn wir nun den Parameter -in hinzufügen , können die Ergebnisse mit der Seitenzahl angezeigt werden, auf der der Begriff gefunden wurde: 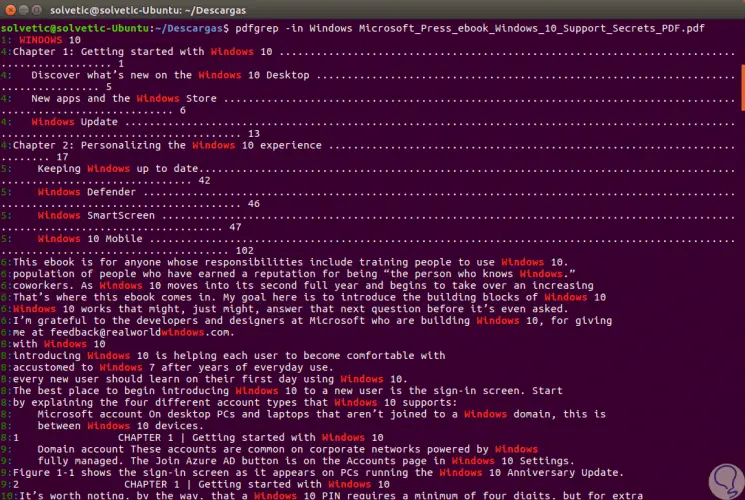
Eine weitere Option, die wir mit pdfgrep verwenden können, besteht darin, die PDF-Dateien aufzulisten, die einen bestimmten Begriff enthalten. Dazu führen wir Folgendes aus:
pdfgrep TechnoWikis * pdf
Auf diese Weise wird die PDF-Datei aufgelistet, in der sich der Begriff TechnoWikis befindet: 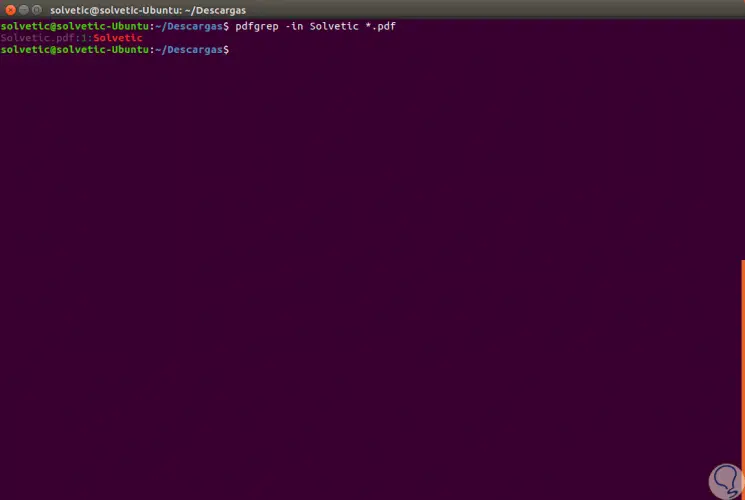
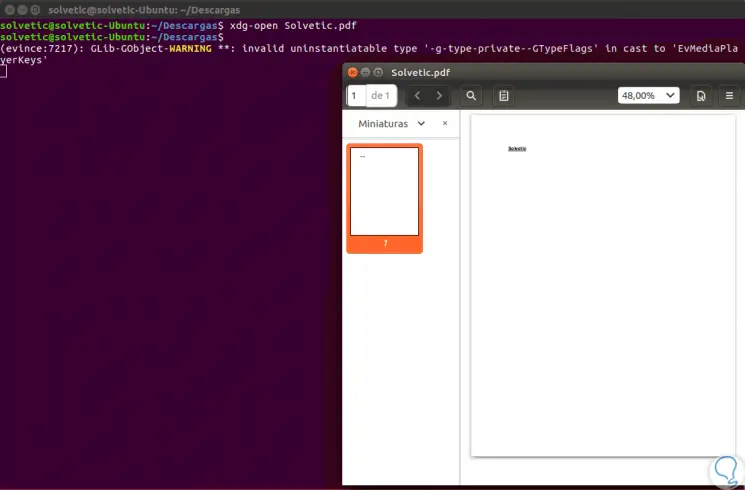
Wenn wir die PDF-Datei öffnen möchten, können wir den folgenden Befehl ausführen:
xdg-open (File.PDF)
Die allgemeinen Optionen von pdfgrep sind:
Mit diesem pdfgrep wird eine ideale Lösung beim Arbeiten mit PDF-Dateien in Linux-Umgebungen.