Um ein Screen Scraping durchzuführen, müssen wir einfach den Inhalt herunterladen und bearbeiten können, damit wir das extrahieren können, was uns interessiert. Dazu können wir verschiedene Techniken verwenden, beispielsweise reguläre Ausdrücke, oder uns mit anderen Bibliotheken wie Tidy helfen.
Was ist ordentlich?
Um ein HTML lesen zu können, müssen wir seiner Struktur vertrauen, da wir nicht genau wissen, welchen Inhalt es hat. Zumindest wissen wir, dass wenn wir nach HTML- Strukturen suchen, die wir erhalten können, das HTML jedoch auch nicht immer gut geformt ist Ein Versäumnisfehler oder weil der Programmierer weiß, dass einige Browser dazu neigen, HTML zu interpretieren, da es einige Fehler gibt.
An diesem Punkt kommt Tidy ins Spiel, das nichts anderes als ein Tool ist, mit dem wir schlecht geformtes HTML reparieren können, das in hohem Maße konfigurierbar ist und das es uns ermöglicht, die Art und Weise anzupassen, in der wir die Korrekturen interpretieren sollen. Auf diese Weise wissen wir mit Sicherheit, was passiert Art des Dokuments wird am Ende führen.
Sehen wir uns zunächst ein Bild eines HTML- Codes mit vielen Fehlern an. Dieser Code kann von einigen Browsern interpretiert werden, ist jedoch in seiner Bildung kein korrekter Code:

Wie wir sehen können, weist jede Zeile einen Fehler auf. Die häufigste ist das Nichtschließen von Beschriftungen. Dann sehen wir Beschriftungen, die an der falschen Stelle geschlossen werden.
Nachdem wir Tidy verwendet haben und den Code bereits korrigiert haben, werden wir die Wichtigkeit dieser Bibliothek und all die Hilfe erkennen, die sie uns geben kann:
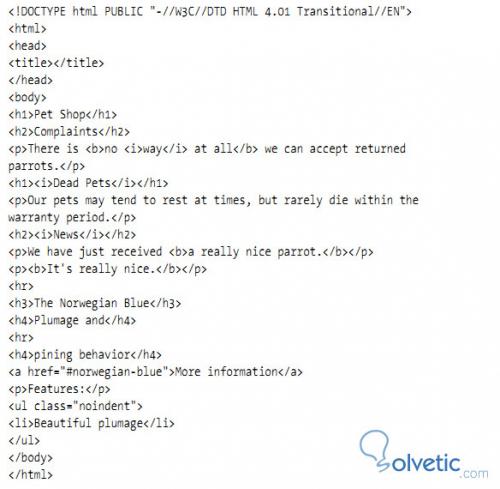
In dem Bild, das wir sehen, wie es von Tidy korrigiert wurde, müssen wir beachten, dass Tidy zwar eine großartige Bibliothek ist, aber wahrscheinlich nicht alle HTML- Fehler beheben kann, aber es hilft uns trotzdem sehr, wenn es darum geht, unser wohlgeformtes HTML zu erstellen.
Holen Sie sich ordentlich
Es gibt mehrere Möglichkeiten, Tidy über die offizielle Website http: //tidy.sf.net zu beziehen . Wir können die Bibliothek erhalten, jedoch gibt es in dieser Quelle keine Möglichkeit, sie in Python zu integrieren. Daher müssen wir auf eine alternative Quelle zurückgreifen. Dafür haben wir zwei Optionen: uTidy verfügbar unter http: // utidylib.berlios.de und mxTidy verfügbar in http: //genix.com/files/python/mxTidy.html , uTidy scheint das aktuellste von beiden zu sein, aber mxTidy ist ein bisschen einfacher zu installieren.
Sehen wir uns ein Beispiel für die Verwendung von Tidy an, sobald es installiert ist. Im folgenden Code öffnen wir ein fehlerhaftes HTML und lesen es mit Tidy. Anschließend werden die Informationen auf dem Bildschirm angezeigt.
aus dem Subprozess-Import Popen, PIPE text = open ('messy.html'). read () ordentlich = Popen ('ordentlich', stdin = PIPE, stdout = PIPE, stderr = PIPE) tidy.stdin.write (text) tidy.stdin.close () print tidy.stdout.read ()
Wie wir sehen können, ist die Verwendung von Tidy recht einfach. Wenn wir genug Vertrauen in das Verhalten der Bibliothek haben, können wir sehr interessante Dinge erreichen.