Diese Formeln befinden sich in regulären Ausdrücken , mit denen wir Muster für die Auswertung von Textzeichenfolgen festlegen und einen positiven oder negativen Wert zurückgeben können, wenn diese Kette der angegebenen Formel entspricht oder nicht.
In Java können wir die regulären Ausdrücke auf einfache Weise implementieren, dies erfordert jedoch eine etwas ausführliche Untersuchung durch den Entwickler, damit Sie die verschiedenen Elemente kennenlernen können, die diesen Ausdrücken zugrunde liegen.
Syntax
Wie wir die Formeln ausdrücken können, mit denen wir unsere Muster mit einer bestimmten Codekonstruktion testen können, nennen wir die Syntax regulärer Ausdrücke .
Im Folgenden finden Sie eine kleine Liste der am häufigsten verwendeten Elemente in regulären Ausdrücken mit Java . Es gibt viel mehr Elemente als die in diesem Lernprogramm gezeigten. Es wird daher empfohlen, eigenständig zu recherchieren, um das Wissen zu vertiefen:
Wie wir anhand dieser wenigen Elemente sehen, können wir mehrere Kombinationen erstellen, mit denen wir relativ komplexe Muster erhalten können.
Testen Sie einen regulären Ausdruck
Wenn wir einen regulären Ausdruck testen möchten, bevor wir ein Programm kompilieren, können wir die rubular.com- Seite verwenden, auf der wir die Muster in Echtzeit auswerten können.
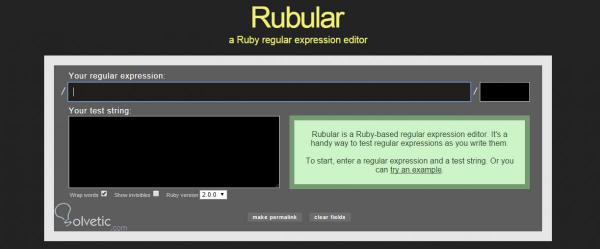
Lassen Sie uns ein einfaches Beispiel machen, in dem wir einen regulären Ausdruck verwenden, um eine E-Mail zu validieren . Wir verwenden Folgendes:
^ [_a-z0-9 -] + (. [_a-z0-9 -] +) * @ [a-z0-9 -] + (. [a-z0-9 -] +) * ( . [az] {2,3}) $
Zuerst müssen wir den regulären Ausdruck in das erste Feld des rubular.com-Seitenformulars eingeben , dann in das Feld mit der Bezeichnung ” Teststring ” , in dem wir verschiedene E-Mails testen , um zu überprüfen, ob der reguläre Ausdruck funktioniert Wenn wir eine ungültige E-Mail eingeben:
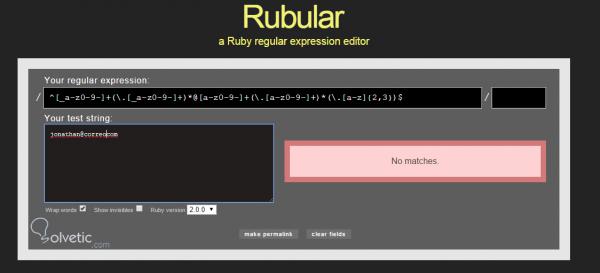
Da in unserer Beispiel-E-Mail der Punkt fehlt, ungültig ist und keine Übereinstimmung mit dem regulären Ausdruck generiert wird, korrigieren wir ihn durch Platzieren des fehlenden Punkts, und der Prüfer generiert automatisch eine positive Antwort, die es uns ermöglicht, den regulären Ausdruck zu erkennen Es funktioniert ohne Probleme.
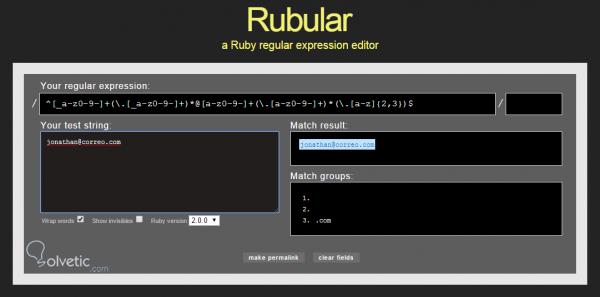
Wie wir zu schätzen wissen, ist dies eine sehr nützliche Ressource, wenn wir lernen, reguläre Ausdrücke nicht nur in Java, sondern in jeder Sprache zu verwenden.
Suche nach Muster
Sobald wir wissen, was die einzelnen Grundelemente der Syntax bewirken, müssen wir lernen, wie wir ein Muster in Java durchsuchen können, damit wir sehen können, welche Methoden, Klassen und Pakete bei der Verwendung regulärer Ausdrücke ins Spiel kommen.
Das Erste, was wir wissen sollten, ist, dass all diese Dienstprogramme im Paket java.util.regex enthalten sind. Um diese Beispiele zu erstellen, müssen wir dieses Paket am Anfang unserer Klassen einfügen.
Sobald dies erledigt ist, können wir ein Muster wie folgt versuchen:
if (ourString.matches (ourExpression)) { // Wenn es hier passt, führen wir einen Code aus }
Wenn wir die Methode matches () verwenden , wird die Zeichenfolge anhand des Musters für reguläre Ausdrücke ausgewertet und true oder false zurückgegeben , falls die Zeichenfolge mit dem Muster übereinstimmt oder nicht.
Diese Art der Verwendung ist in kleinen Validierungen in Ordnung. Wenn wir jedoch eine wiederkehrende Validierung verwenden, das heißt, es wird in unserem Programm häufig vorkommen, ist es am besten, eine kleine Routine oder Klasse zu erstellen, mit der wir die Zeichenfolge auswerten können parametrische Form, dh eine Routine oder Methode, mit der wir eine Zeichenfolge eingeben können und die beim Vergleich mit einem bestimmten Muster “true” oder “false” zurückgibt.
Im folgenden Programm werden wir ein kleines Muster testen und es anhand einiger Ketten oder Strings auswerten. Das Programm wird uns mitteilen, welche Übereinstimmung, dh welche Übereinstimmung und welche nicht, den Code sehen und dann seine Funktionsweise sehen:
import java.util.regex. *; public class PruebaPatrones { public static void main (String [] argv) { String pattern = "^ Q [^ u] \ d + \."; String [] input = { "QA777 ist die Kennung unseres Produkts.", "Quacksalber, Quacksalber, Quacksalber!" }; Pattern p = Pattern.compile (pattern); für (String in: Eingabe) { boolean found = p.matcher (in) .lookingAt (); System.out.println ("'" + Benutzer + "'" + (gefunden? "passt zu '": "passt nicht zu'") + in + "'"); } } }
Hier sehen wir, wie wir zuerst das am Anfang dieses Abschnitts erwähnte Paket importieren, um die Suchfunktionen durch reguläre Ausdrücke zu erhalten. Dann erstellen wir ein Muster, das wir als unser Programm verwenden. In diesem Fall ist es ein Muster, das mit dem Buchstaben ” Q ” übereinstimmt. Dann muss es ein beliebiges Zeichen mit Ausnahme des Buchstabens ” u ” haben und mit einem Punkt enden. Dann kompilieren wir unser Muster mit der Kompilierungsmethode und können damit die Übereinstimmungen herstellen. Schließlich, wenn das Muster übereinstimmt, wird mit dem Wort Übereinstimmungen gedruckt , sonst drucken wir nicht übereinstimmen .
Sehen wir uns im folgenden Bild an, wie das aussieht, wenn wir das Programm ausführen:
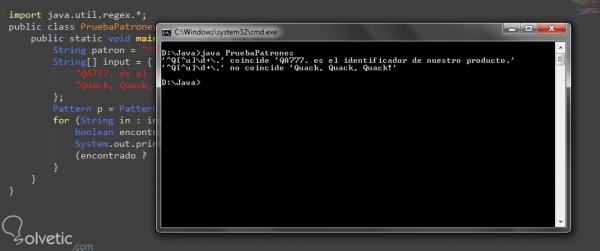
Wir bemerken dann, wie die erste Zeichenkette oder die erste Zeichenkette erklärt wird, wenn sie übereinstimmt, die zweite jedoch nicht, und zum besseren Nachschlagen platzieren wir das Muster, auf dem der Vergleich durchgeführt werden soll.
Identifizieren Sie, welcher Teil der Zeichenfolge übereinstimmt
Jetzt werden wir ein etwas ausführlicheres Beispiel erstellen, in dem wir herausfinden, welcher Teil unserer Zeichenfolge übereinstimmt. Dies ist sehr nützlich, wenn wir im Text suchen, da wir damit die Übereinstimmungen hervorheben können, die der Benutzer eingibt.
Dazu verwenden wir die gleiche Basis wie in unserem vorherigen Programm mit einigen Modifikationen. Sehen wir uns den Code und dann die Erklärung an:
import java.util.regex. *; public class QueCoincide { public static void main (String [] argv) { String pattern = "Q [^ u] \ d + \."; Pattern r = Pattern.compile (pattern); String text = "Die ID lautet: QW990. Ende des Tests!"; Matcher m = r.matcher (Text); if (m.find ()) { System.out.println (Muster + "stimmt mit " "+ überein m.group (0) + "" innerhalb von "" + Text + ""); } else { System.out.println ("Keine Übereinstimmungen"); } } }
Wieder einmal sehen wir, wie wir unser Programm einschließlich des Pakets java.util.regex. * Gestartet haben . Dann verwenden wir dasselbe Muster aus dem vorherigen Programm und kompilieren es mit der compile- Methode. Das Interessante ist nun, dass wir die matcher () -Methode zum Auffinden der Übereinstimmung verwendet haben und dann mit der find () -Methode und der group () -Methode genau das extrahieren können Streichhölzer machen wir endlich die entsprechenden Bildschirmabdrücke. Mal sehen, wie unser Programm jetzt aussieht:
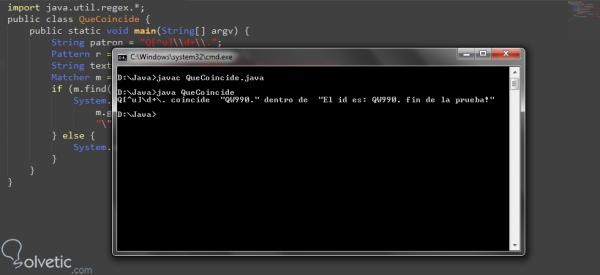
Wir sehen also, wie wir das Wort isolieren können, das wirklich dem Muster entspricht, das wir für den Vergleich des regulären Ausdrucks festgelegt haben .
Anwendungen von regulären Ausdrücken
Eine der am häufigsten verwendeten Anwendungen sind Formulare , mit denen wir E-Mails, Telefonnummern, Kreditkarten, Kennwörter, IP-Adressen, Benutzernamen und Postleitzahlen überprüfen und sogar überprüfen können, ob alle unsere Tags in unserem HTML-Dokument korrekt sind Dies gibt uns die Möglichkeit, eine größere Sicherheit bei der Verarbeitung von von Benutzern eingegebenen Texten zu erreichen.
Aber nicht nur bei Validierungen in Feldern eines Formulars, wie wir in unserem letzten Beispiel festgestellt haben, können wir auch in Langtexten nach einem bestimmten Muster suchen, mit dem wir systematisch in sehr komplexen Textdokumenten suchen und so viel Geld sparen Zeit, einfach durch Schreiben eines kleinen Programms.
Nachdem wir dieses Tutorial abgeschlossen haben, haben wir gelernt, wie wir von verschiedenen Elementen zu Expressionssituationen innerhalb unserer Muster übergehen können, bis wir die entsprechenden Vergleiche des zu bewertenden Texts oder der zu bewertenden Zeichen mithilfe der regulären Ausdrücke durchführen . Diese Auswertungen sind dank der Optimierungen, die die Sprache in den von ihr angebotenen Methoden vornimmt, recht schnell. Aus diesem Grund eignen sie sich sehr gut für die Erstellung von Schnittstellen, in denen vom Benutzer eingegebener Text gesucht und validiert werden muss.